論文2: SArF Map
- 論文1 の技術の応用。
- ソフトウェアの構造を都市として 表すというアイデアは古くからある…らしい (CodeCity, 2007).
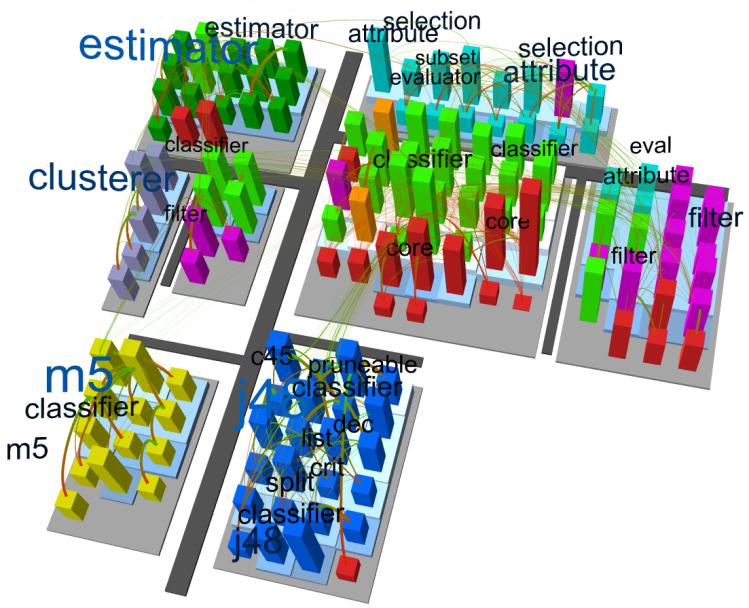
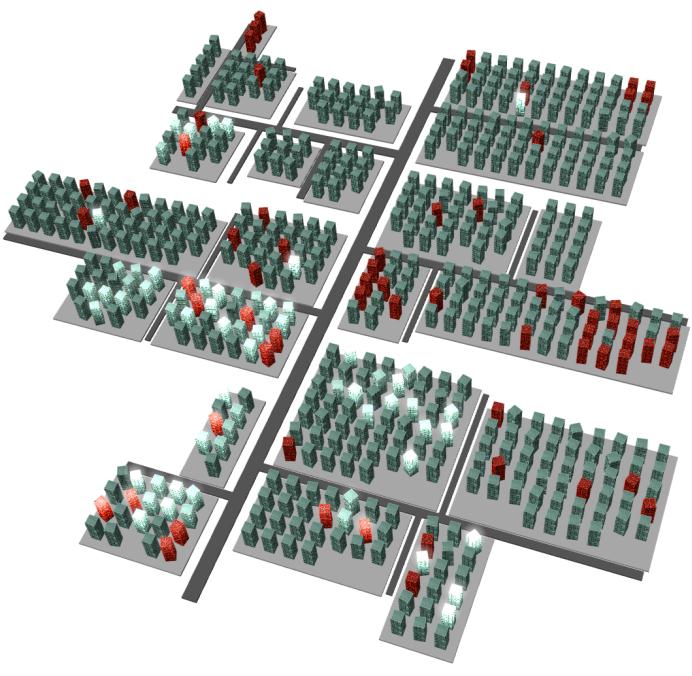
a と b が一致しているとき、 そのソフトウェアはベストな状態といえる。
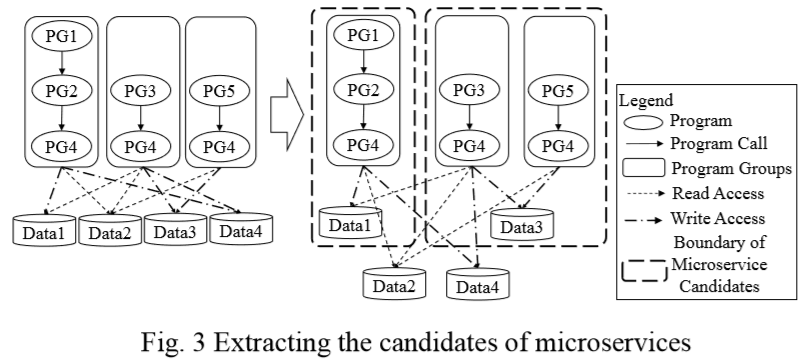
| Elements | Java | COBOL |
|---|---|---|
| API | @Control | メインプログラム |
| Data | @Entry / @Table | DBファイル |
| Program calls | メソッド呼び出し | CALL文 |
| Write | メソッド名 set〜 | テーブル作成および更新 |
| Read | メソッド名 get〜 | File参照のTable文 |