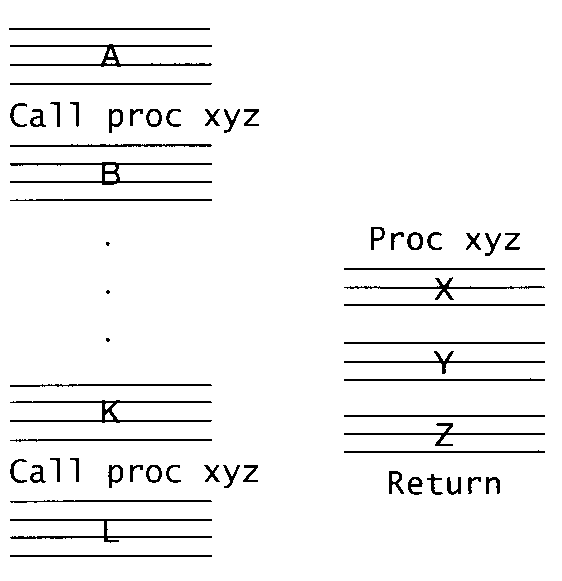第4章の概要
- 「互換性ができたら、つぎは最適化の番」
- 4.1. 最適化が努力に見合うわけ
- 4.2. プロファイリングの各種方法
- 4.3. 実際の最適化
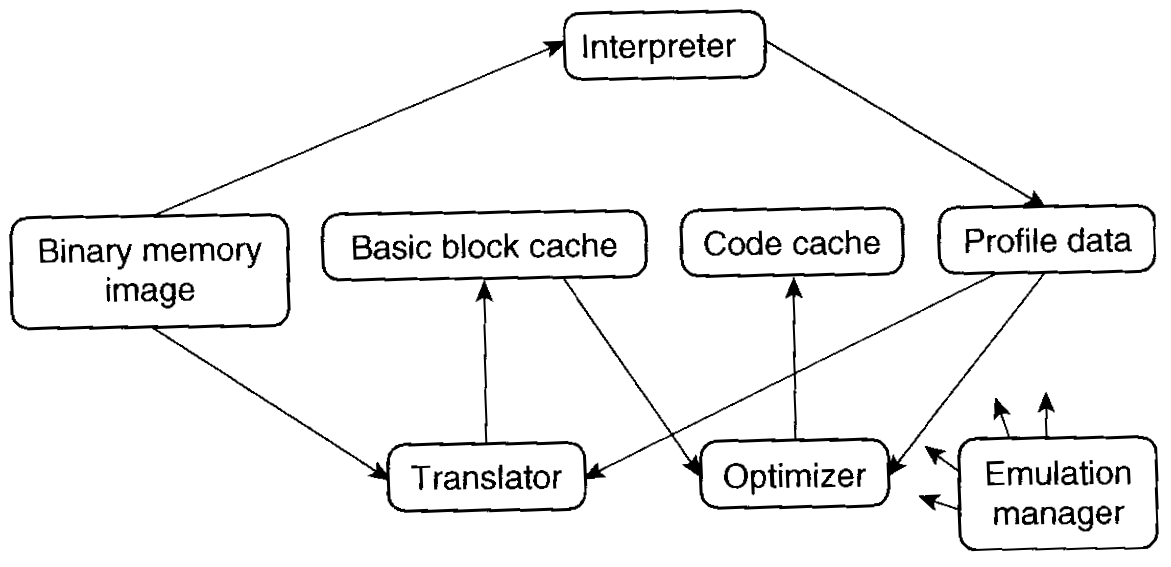
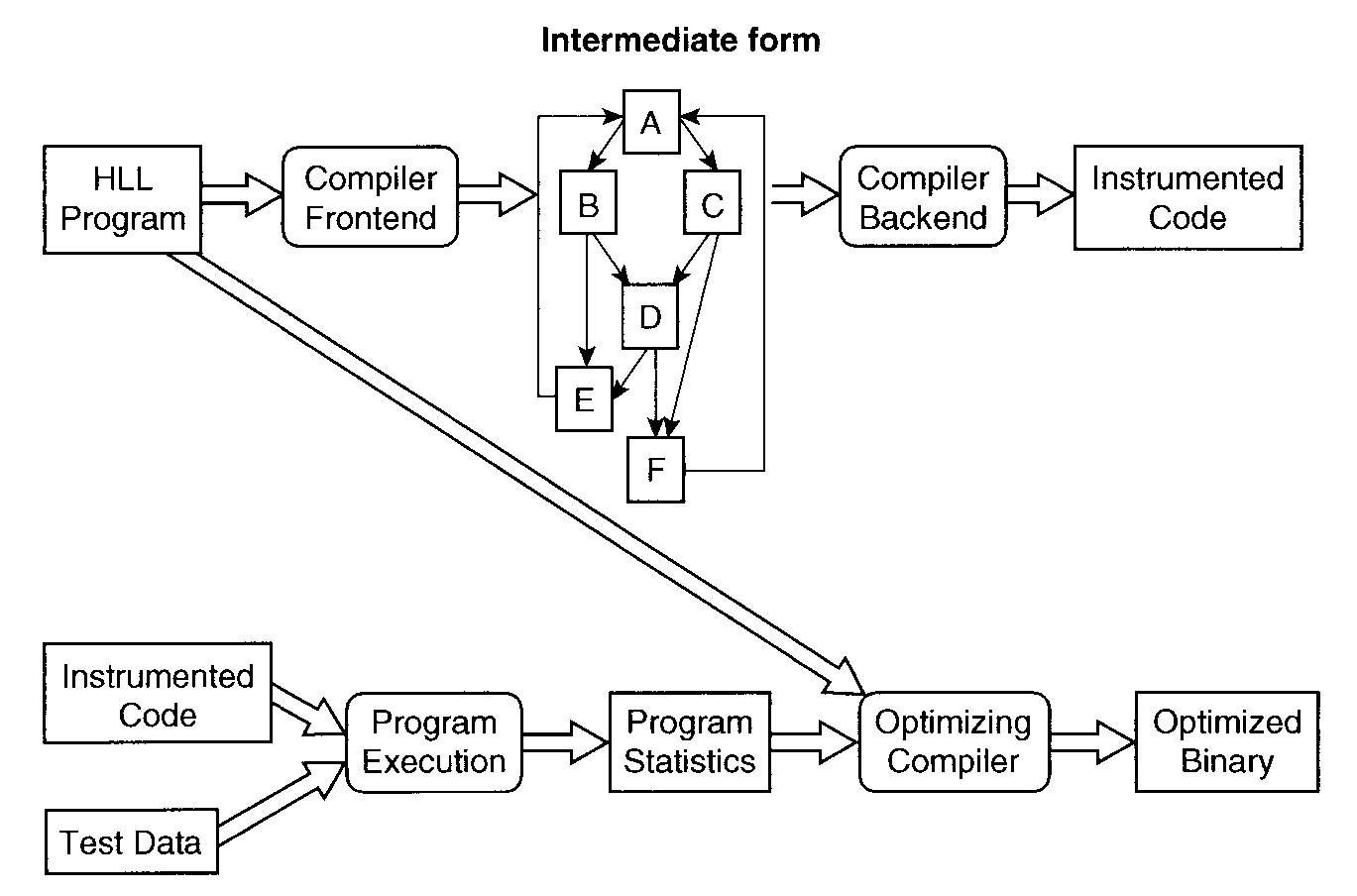
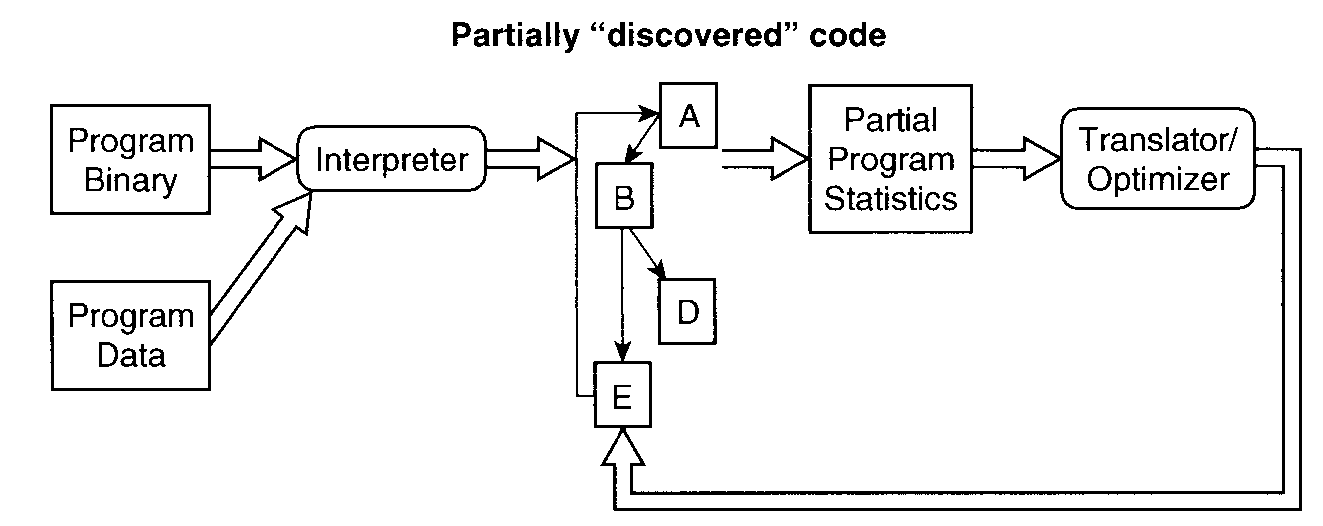
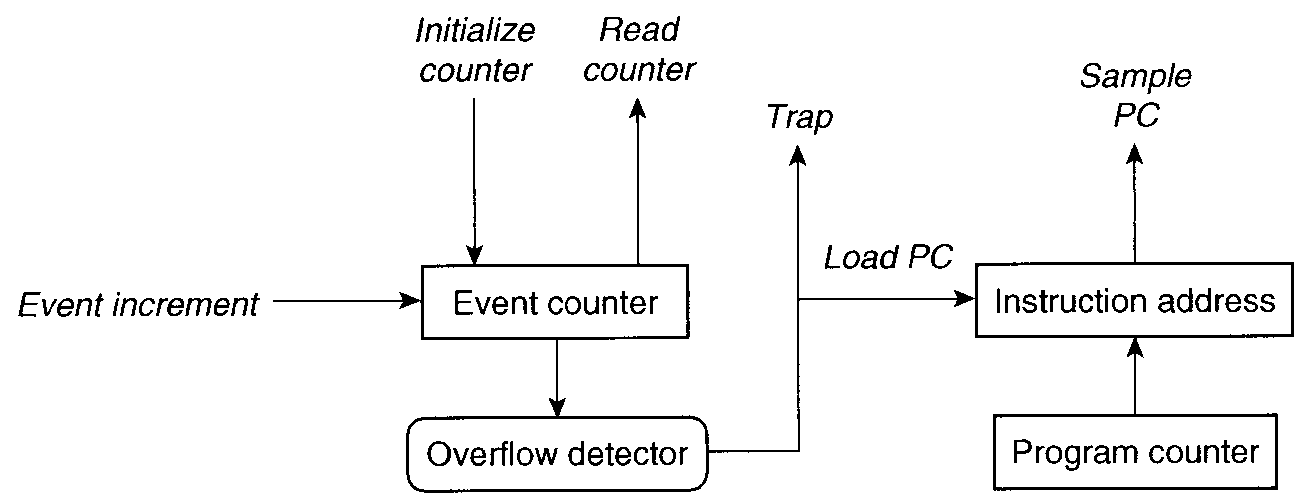
注意: ここでいう「最適化」とは、
ネイティブに変換されたバイナリの最適化である。
そうすると...
→ 99% の確率で 1命令トクする。これが最適化。
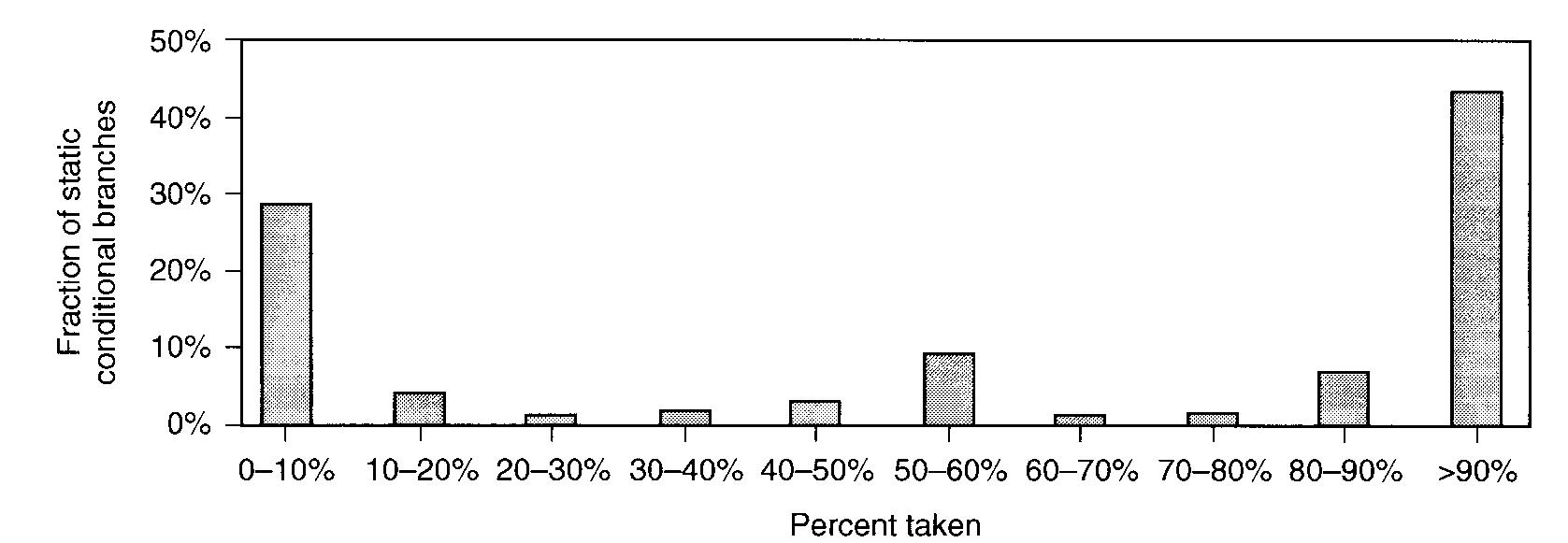
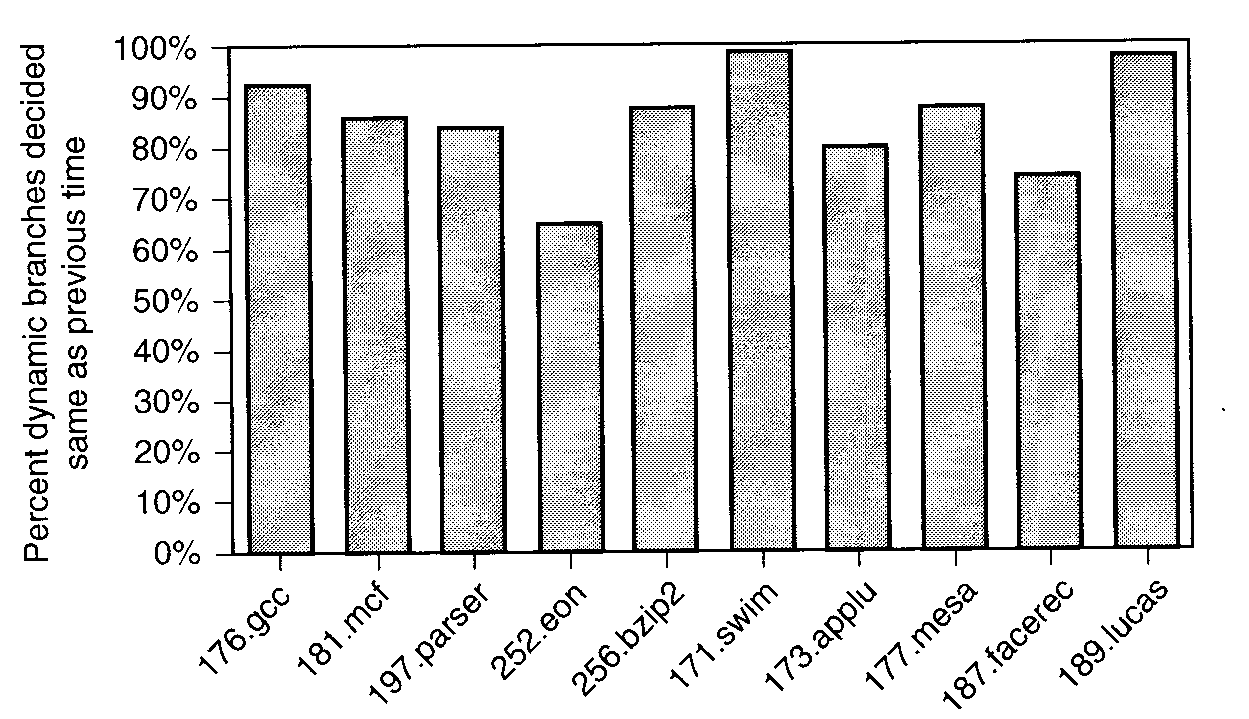
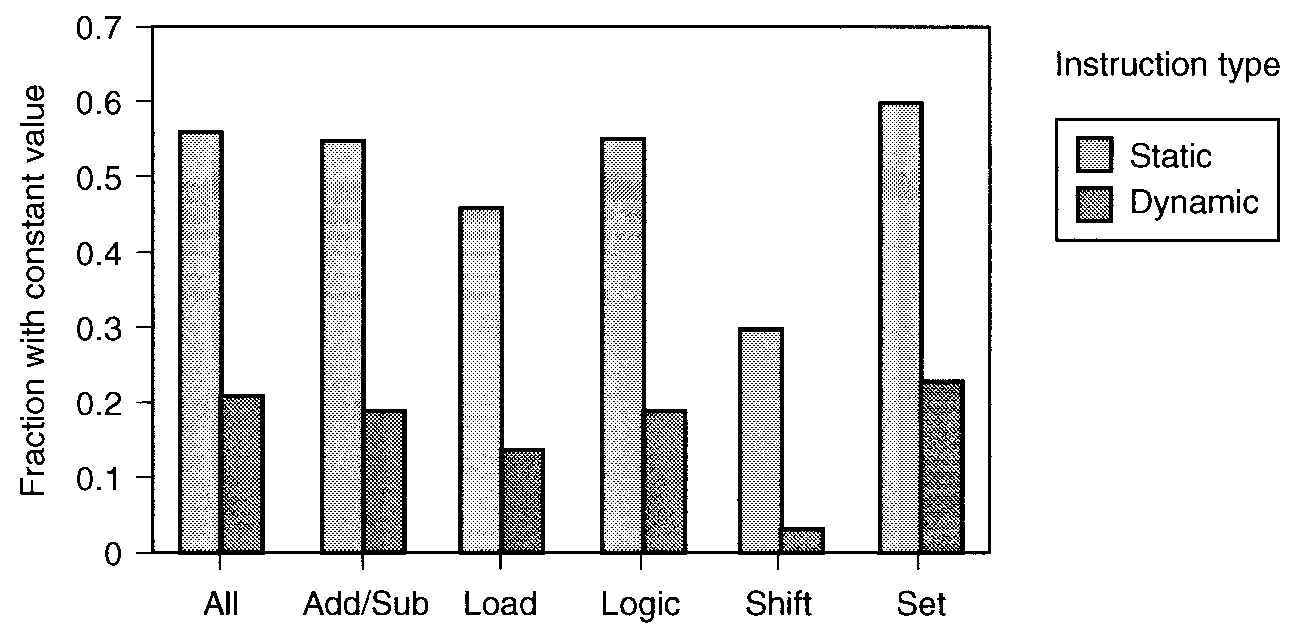
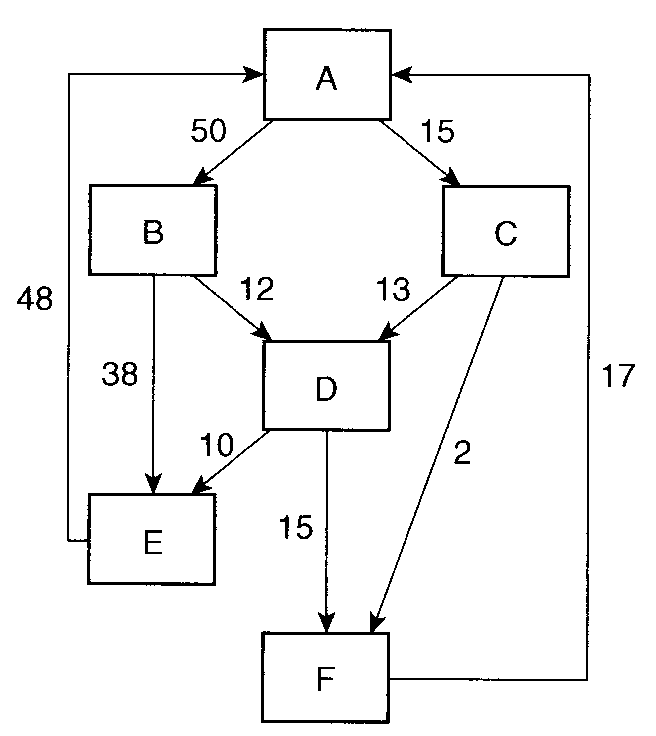
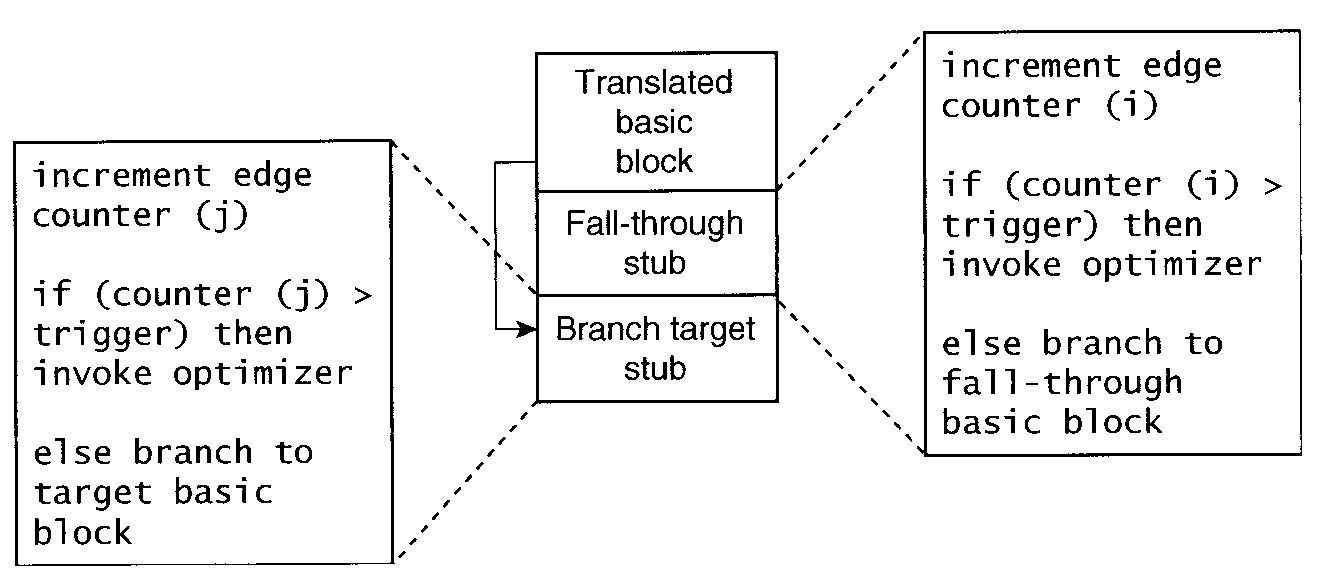
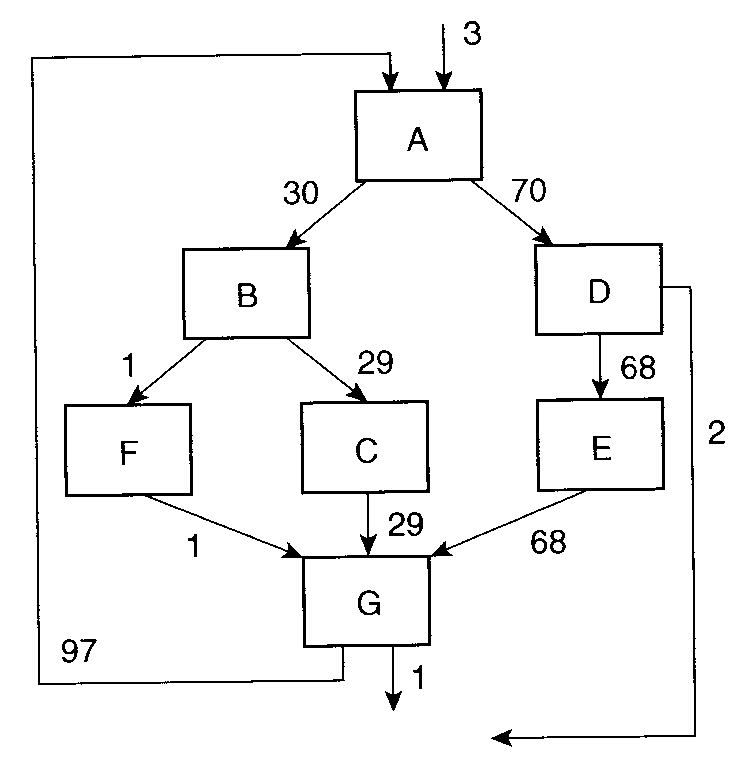
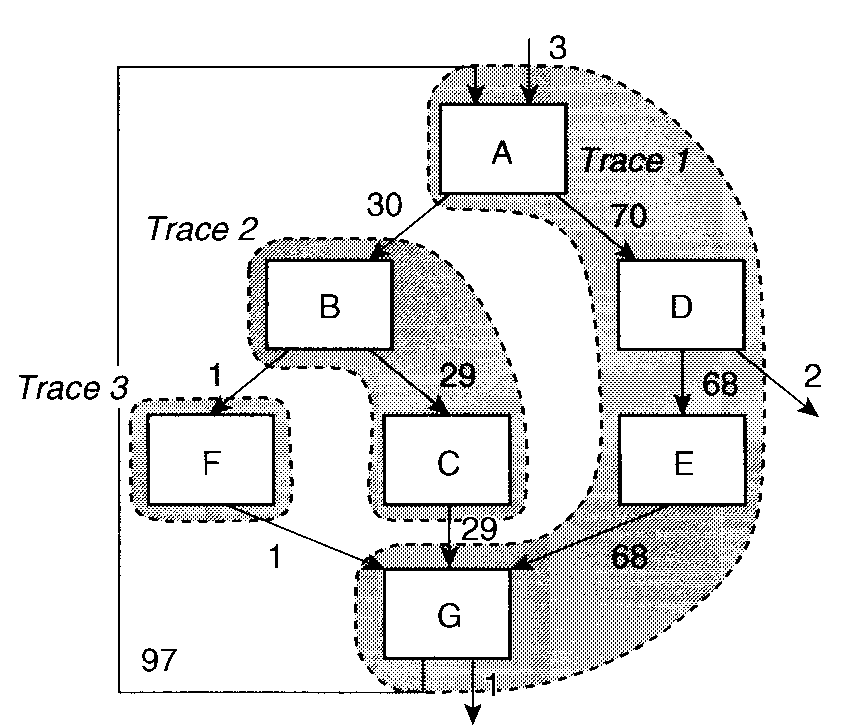
エッジ・プロファイル
- 「各分岐を何回通ったか」を記録する。
- ノード・プロファイルより手間がかかるが、
これがあればノード情報もわかる。
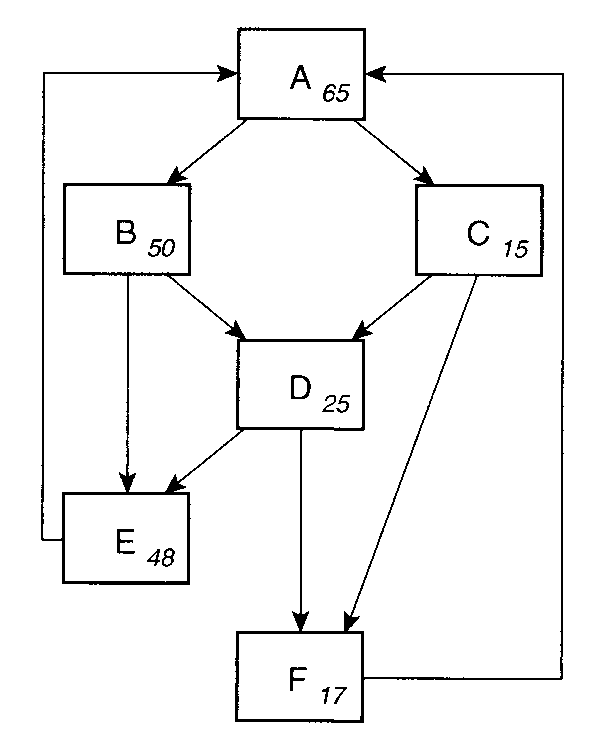
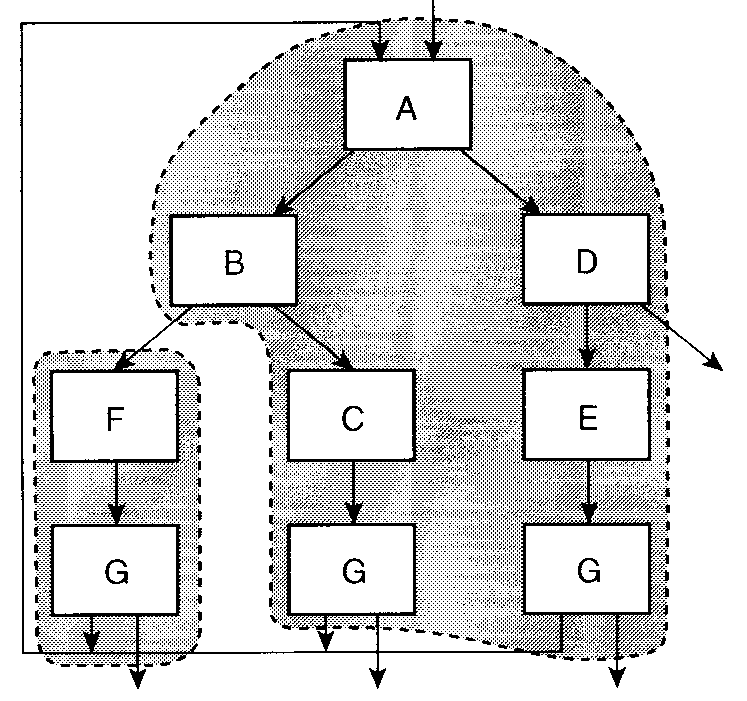
問. 上の図で、ブロック D は何回実行されるか。
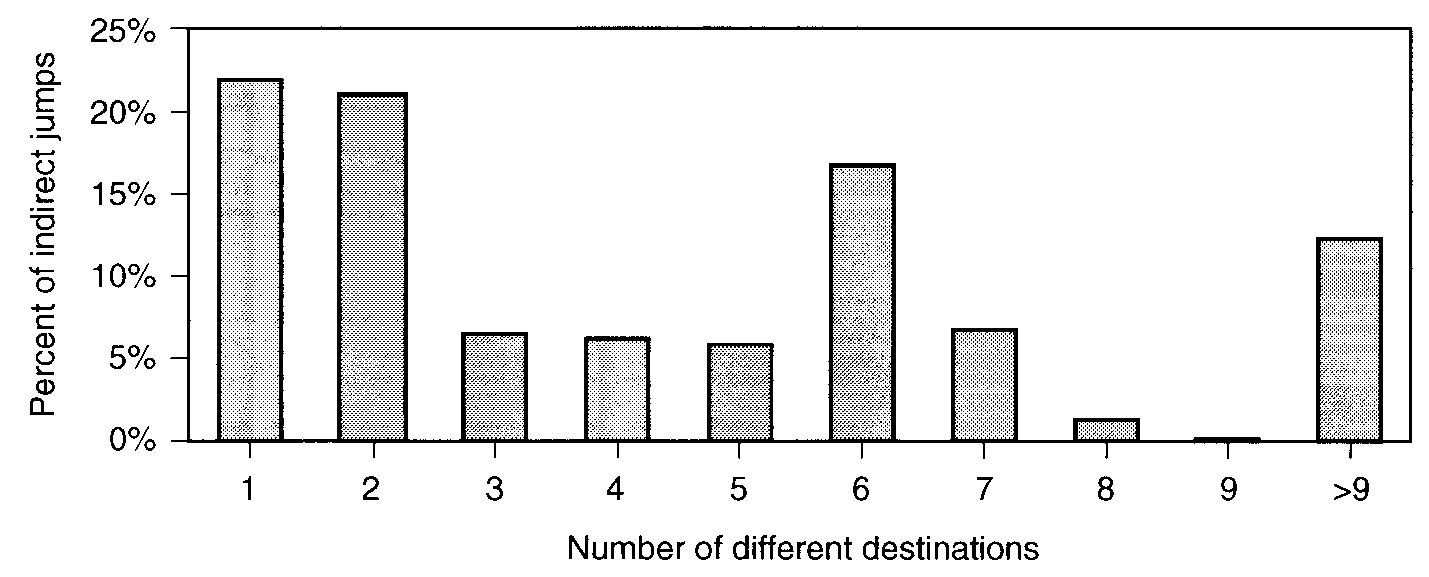
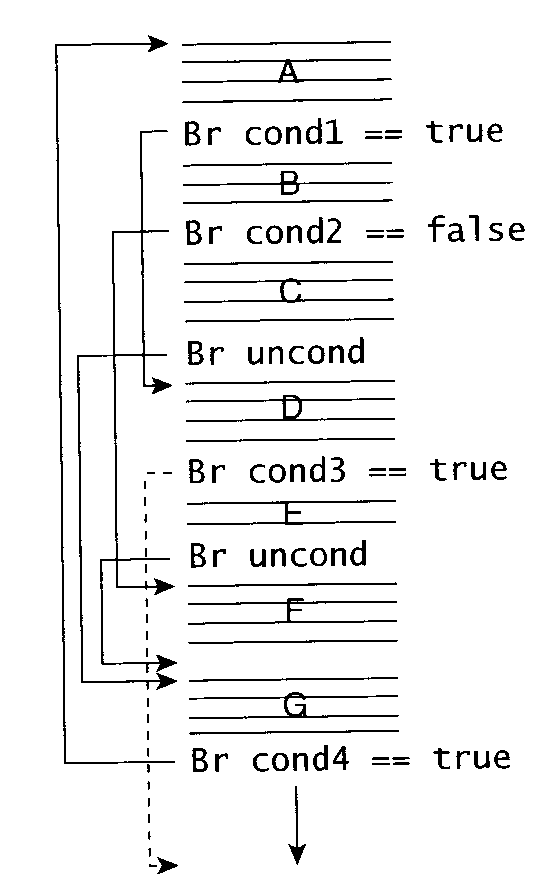
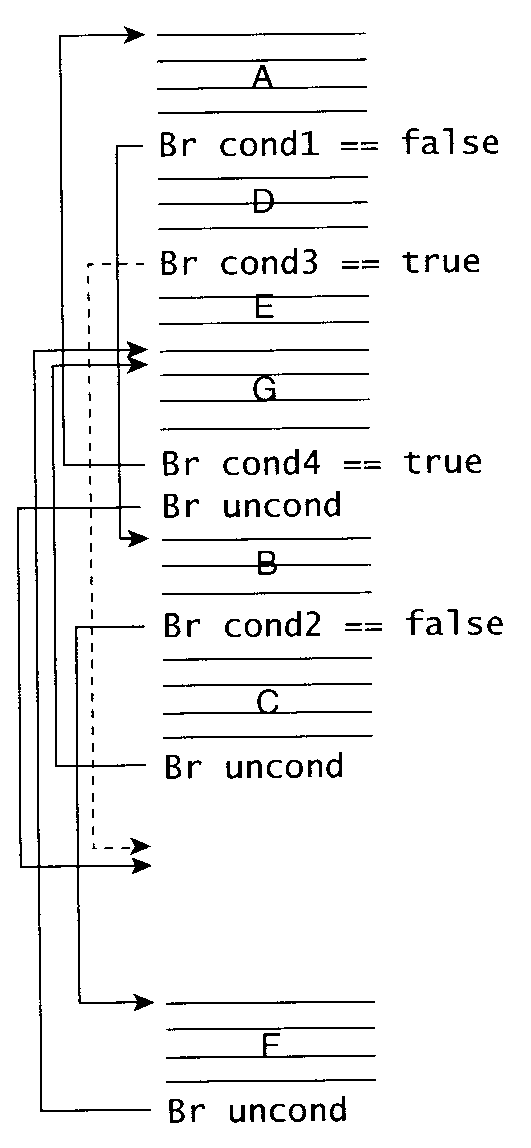
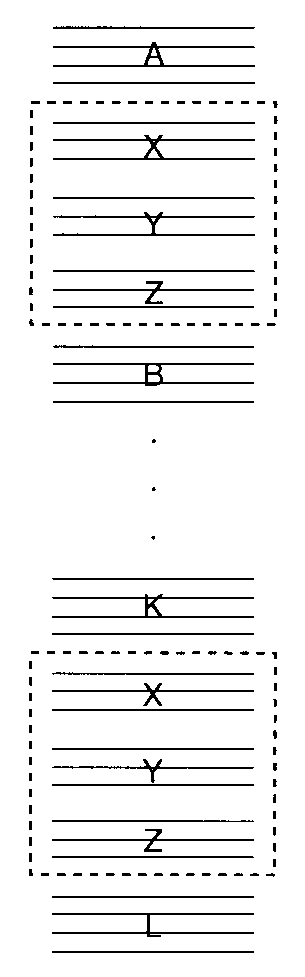
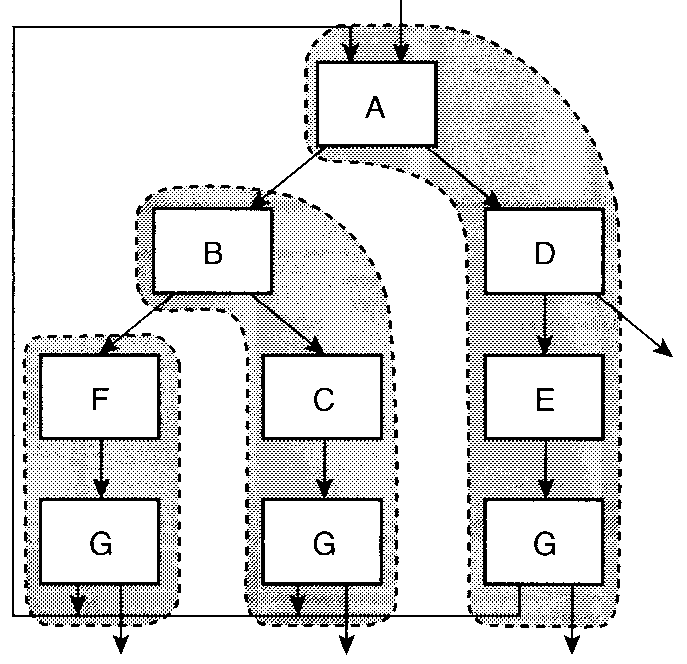
"Trace" を使う方法
- よく実行される手続きを複製して埋め込むことで、局所性を改善できる。
- もっともよく実行されるブロックから始める。
- 次によく実行されるブロックをつなげる。...
- 出口に到達するか、なくなるまで繰り返す。
問. 上のアルゴリズムに従って、trace を作成せよ。
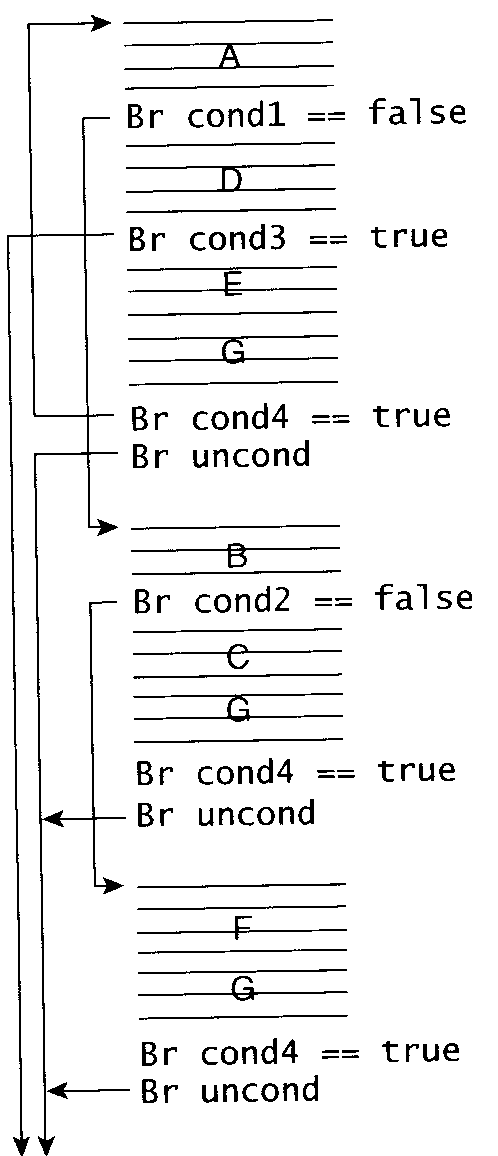
Step 1. 最初のブロックを見つける
- 開始しきい値 (Start threshold) という概念を使う。
- これを超えたら Superblock の構築を始める。
問. Start threshold = 100 のとき、該当するブロックはどれ?
練習問題
- 以下のブロックから superblock を MFU で構築する:
問. Cont. threshold = 50 のとき、Continuation Set を求めよ。
問. フローに従って、Superblock を構築せよ。