「分類」は、たとえば以下のような状況で使われる:
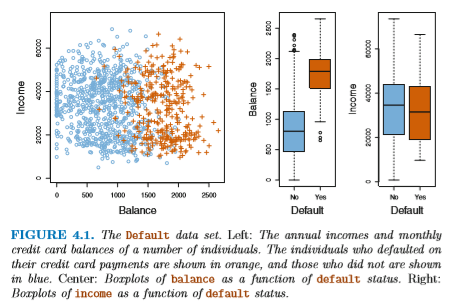
この章では、あるクレジットカード利用者の 収入 (income) と利用額 (balance) から、 その利用者が債務不履行 (default) を起こすかどうかを 決定するタスクを例として利用する。 ここでの分類の結果は "Yes (True)" あるいは "No (False)" のどちらかである。 このような分類器を binary classifier という。 (これは 10,000件の利用者データからなるが、 実際に債務不履行を起こす利用者は全体の 3% である。) ちなみに "債務不履行データ" では、 利用額と不履行の可否に大きな相関があることがわかっている。
上記の例 a. を線形回帰でやろうとして、 予測する値 y を以下のように決めるとする:
y == 1 : 心臓発作
y == 2 : 薬物中毒
y == 3 : てんかん
あるいは、3つのケースごとに独立した確率を線形回帰で モデルするという手もある:
y == 0 : 債務不履行の確率 0%
y == 1 : 債務不履行の確率 100%
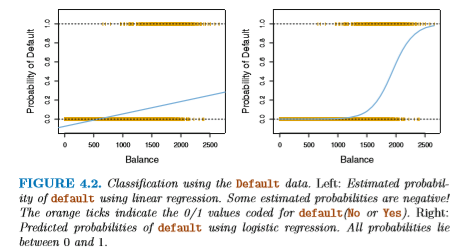
ここでは線形回帰のかわりに、確率をモデル化するのに 適したロジスティック回帰 (logistic regression) を使う。
確率を、以下のような関数でモデル化することを考える:
| p(X) | = | exp(a + bX) / |
| (1 + exp(a + bX)) |
この式を変換すると、以下のようになる:
ここで p / (1 - p) は、オッズ (odds) を表している。 オッズは確率を別の方法で表したもので、 競馬などの賭け事における払い戻し金を計算するのによく使われる。
ロジスティック回帰の学習では、パラメータ a と b を推定する。 このとき、
これは以下のような Likelihood 関数を最大化するような a と b を求めることにより決まる (maximum likelihood 法):
| L(a, b) | = | p(XP0) × p(XP1) × ... × p(XPn) × |
| (1 - p(XN0)) × (1 - p(XN1)) × ... × (1 - p(XNn)) |
たとえば「債務不履行データ」の場合、 ロジスティック回帰は、
債務不履行 == Yes | ある利用額)
p > 0.5 なら「ヤバい」と判断すればよい。
(別のしきい値を使う手もありうる)
ロジスティック回帰に入れる素性は複数あってもよい。 この場合、確率を
| p(X) | = | exp(a + bX) / |
| (1 + exp(a + bX)) |
| p(X) | = | exp(a + bx1 + cx2 + ... ) / |
| (1 + exp(a + bx1 + cx2 + ... )) |
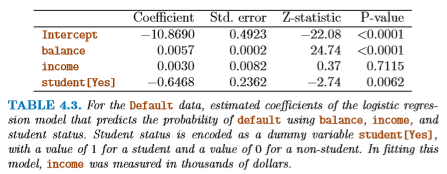
これを使って「債務不履行データ」を
balance, income および
student? の3つの素性でモデル化すると、
素性 student? は債務不履行に対して負の相関があることがわかる。
いっぽう、student? だけの素性を使うと
student? == Yes であるほど
債務不履行 == Yes しやすいという結果になる。
これはなぜなのか?
実は balance が同じであれば student? == Yes のほうが
債務不履行 == Yes の確率が低い。
ただし学生は一般に balance がより高いので、
総合的に債務不履行 == Yes に寄与しているというわけだった。
Rを使えばできるけど、ここではやらない。
注意: Linear Discriminant Analysis は通称 LDA と略されるが、 自然言語処理の分野で LDA (Latent Dirichlet Allocation) という、 まったく別の学習モデルもあるので混同に注意。
ロジスティック回帰は
Y==k | X==x)
まず密度関数 (density function)
Y==k)
Bayes の定理により
P(Y==k | X) | = | P(Y==k) × fk(X) / |
sum(P(Y==i) × fi(X)) |
実際には fk(X) の形を 仮定しないと推定は難しい。LDA では fk(X) をガウシアン関数
| fk(X) | = | exp(-1/(2×σk2) × (X - avgk(X))2) / |
| (sqrt(2×PI) × σk) |
素性が1つしかない場合は簡単である。 まず、簡単のため
P(Y==k | X) | = | P(Y==k) × exp(-1/(2×σ2) × (X - avgk(X))2) / |
sum(P(Y==i) × exp(-1/(2×σ2) × (X - avgi(X))2) |
Y==k | X)
Y==k))
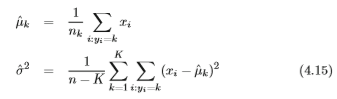
Y==k) を求める。(数えるだけ)
例として |k| = 2、P(Y==0) = P(Y==1) = 0.5 と仮定すると
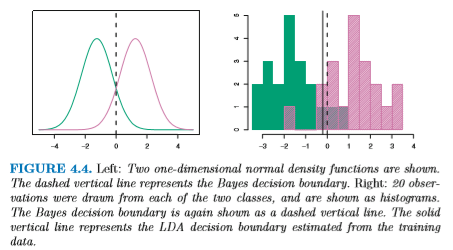
変数が 2つある場合、 σ のかわりに共分散行列 Cov(X1, X2) を使う。 共分散行列は 2つの分布の幅および傾きを指定する。
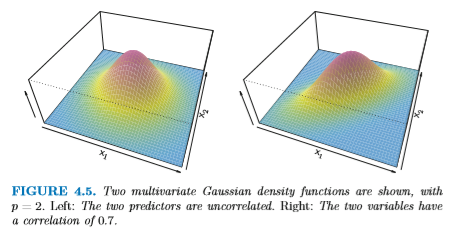
ここでも、簡単のため Cov は各 k に対して同一であると仮定する。
実際にプログラムしてみた例 (自信なし):
"債務不履行" タスクの場合、 分類の間違いには2種類のエラーが存在する。 つまり「本来 Yes のはずのものを No と判定した」場合と、 「本来 No のはずのものを Yes と判定した」場合である。 これらを表 (行列) の形式で記したものを Confusion Matrix とよぶ。
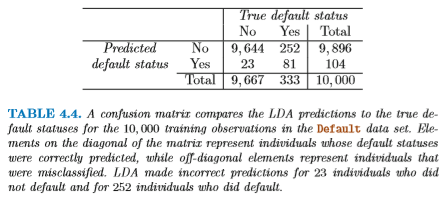
じつは、この分類結果には実用上の問題がある。
本来「債務不履行 == Yes であるものを No と判定してしまった」
エラーが多いのである。これは 2種類のエラーの合計を
最小化するようにしたためであるが、実際のクレジットカード会社にとっては
一方のエラーのリスクのほうが、他方のエラーのリスクよりも大きい。
そこで「債務不履行 == Yes」の確率を重視することにして、
従来までは P(債務不履行 == Yes) > 0.5 であれば
「Yes」と判定していたものを、
P(債務不履行 == Yes) > 0.2 であれば
「Yes」と判定するようにする。
すると、confusion matrix は以下のようになる:
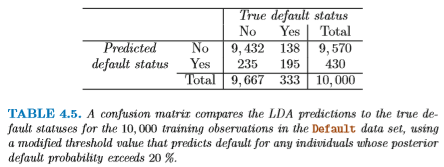
こうすると、クレジットカード会社の恐れるエラーは減少する。 が、全体的なエラーの合計は増えてしまう。
このような機械学習のトレードオフを表現するために、 ROC Curve というものがよく使われる。 これは True Positive (正しく判定できた Yes の割合) と False Positive (間違って Yes と判定されたものの割合) を それぞれ縦軸・横軸に表したもので、左上にいけばいくほどよく、 曲線の右下部分の面積がその学習アルゴリズムの「能力」を 表すと考える。
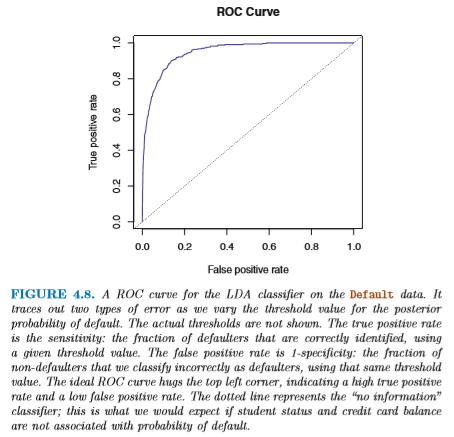
実際の文献では、True Positive, False Positive などの割合は いろいろな用語で呼ばれている。以下に代表的なものを示す:
| 指標 | 使われる用語 |
|---|---|
| |間違った Yes 判定| / |すべてのYes物件| | Type 1 error, 1-Specificity |
| |正しい Yes 判定| / |すべてのYes物件| | 1-Type 2 error, Power, Sensitivity, Recall |
| |正しい Yes 物件| / |Yes判定されたもの| | Precision, 1-False dicovery proportion |
| |正しい No 物件| / |No判定されたもの| |
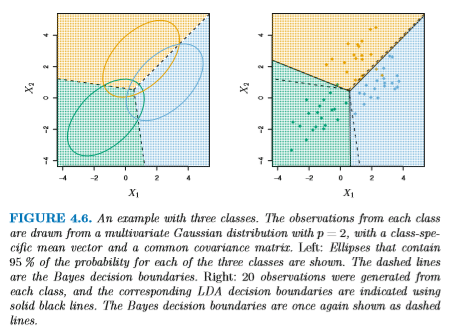
これまでの例では、σ または Cov がすべての k に対して 同一の場合を仮定していた。これが各 k ごとに異なると仮定すると、 先の argmax の式は
Y==k))
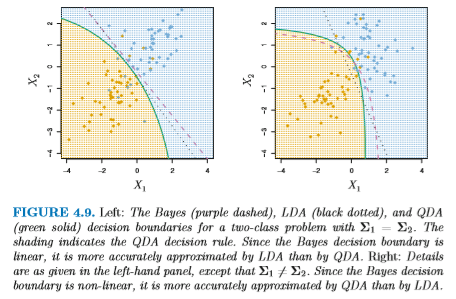
QDA はより複雑な形状の分布を表現できるため柔軟性は高いが、 同時に学習しなければならないパラメータが |k| p × (p+1) / 2 個に なってしまう。少ないデータでは、これは過学習の危険性がある。 Bayes 境界が直線の場合、QDA よりも LDA のほうが 適していることもある (下図)。