第1回 プログラマのためのPython入門
はじめに、
本講座のコードを読むために必要な Python の基礎知識と、
有用な tips をいくつか紹介する。
Python は動的な型付けをもつスクリプト言語であり、
JavaScript や Ruby に似ている部分が多いが、いくつか重要な違いがある。
このページの使い方:
各セクションはすぐに読める程度の長さになっているので、
特定の箇所だけをつまみ読みすることを想定している。
すべて読む必要はない。
他言語に慣れている人への注意は、このような囲みで示した。
はじめて Python を使う
Python の基本
Python の拡張機能
1. はじめて Python を使う
1.1. Pythonのインストール
以下に Python をインストール・実行する代表的な 3つの方法を挙げる:
Python 本家 で配布されているバージョンを使う方法:
Anaconda から配布されている Jupyter Notebook を使う方法:
長所: 最初から多くの機能が使える。
短所: 巨大かつ複雑なシステムであり、
内部で何が起きているのかが見えにくい。
手順:
Anaconda システム
をダウンロードし、インストールする。
(10GB程度のディスク空き容量が必要)。
Google Colaboratory を使う方法:
長所: PCの知識があまりなくても使える。インストールは必要ない。
短所: Googleアカウントが必要。ブラックボックスな部分が多い。
手順: Google アカウントを作成し、
Colaboratory にログイン する。
本講座では、おもに Windows で上記 a. のケースを想定して説明しているが、
b. および c. の環境を使っていても支障はない。
1.2. テキストエディタ (VS Code) のインストール
上記 a. の方法で Python のみをインストールした場合、
簡単なテキストエディタをインストールしておくことが望ましい。
Visual Studio Code (以下 VS Code) は高機能なテキストエディタで、
Python のプログラムを書いたり実行したりするのにおすすめである:
まず
https://code.visualstudio.com/ に
アクセスし、VS Code をダウンロードする。
macOS の場合:
「アプリケーション」フォルダにアイコンをドラッグ・ドロップし、
起動後に Install 'code' command in PATH を実行する。
詳細 。
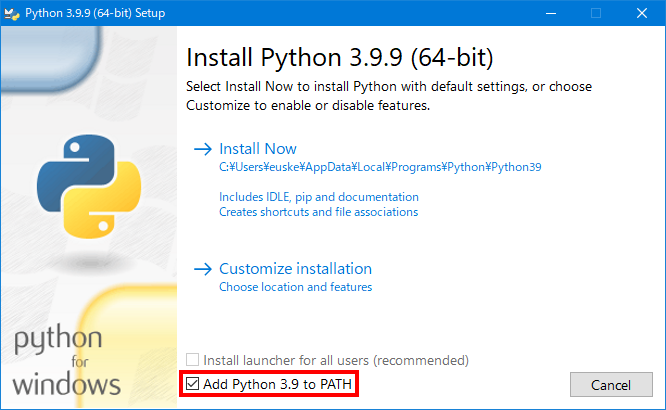
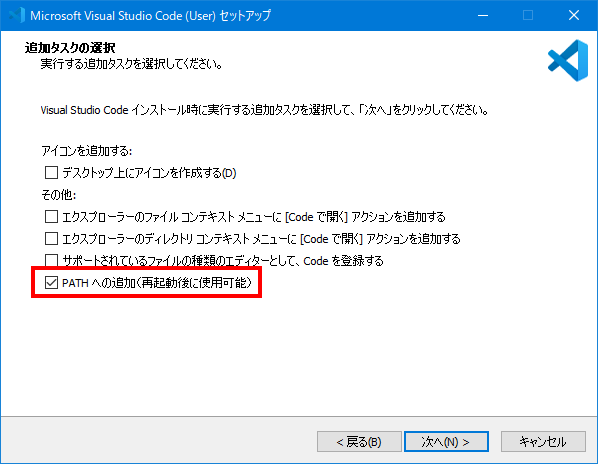
Windows の場合:
PATHへの追加 をチェックしておく。
詳細 。
VS Code が正しくインストールされると、
コマンド プロンプト上で code コマンドを
使ってエディタを起動することができる:
C:\Users\euske> code hello.py
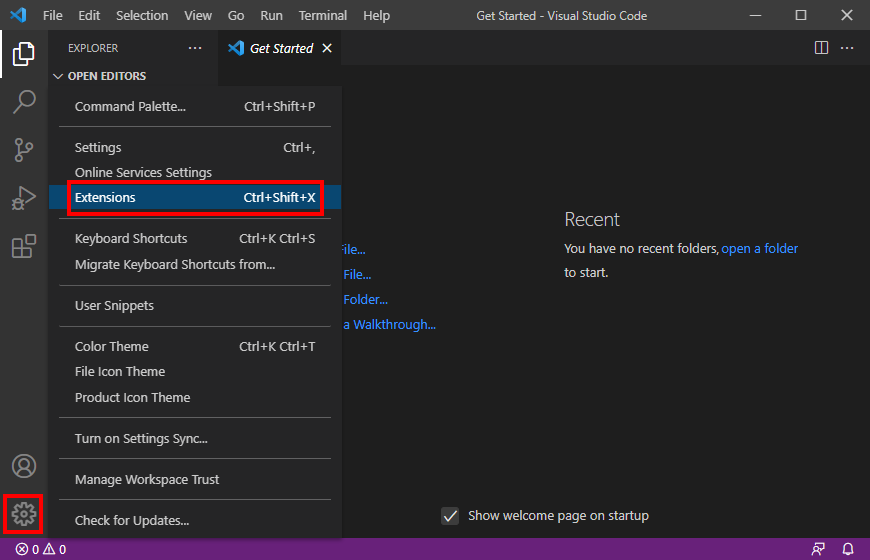
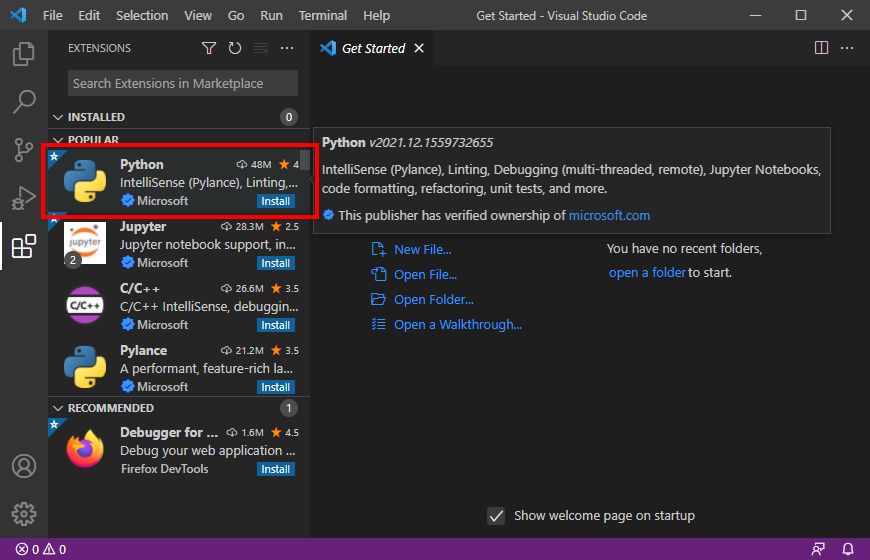
インストールが終わったら、左下の歯車アイコンをクリックして
Extensions (拡張機能) を選ぶ。
ここでさらに Python を選択し、インストールする。
1.3. Pythonプログラムの実行
スタンドアロンの Python を使う場合
Pythonプログラムを実行するには、適当なテキストエディタで
スクリプトを作成後、シェル (コマンドプロンプト) から以下のように入力する:
いずれの場合も、スクリプト名を省略して python のみを実行すると、
対話モード で使うことができる。
これはちょっとした計算や実験をしたいときに便利である:
C:\Users\euske> python
Python 3.9.9 (tags/v3.9.9:ccb0e6a, Nov 15 2021, 18:08:50) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("hello, world!")
hello, world!
>>> 2+3
5
プログラムがループで止まらない場合は、
Control + C を押して止める。
こうするとインタプリタ内部で KeyboardInterrupt 例外が発生し、
Python は終了する。
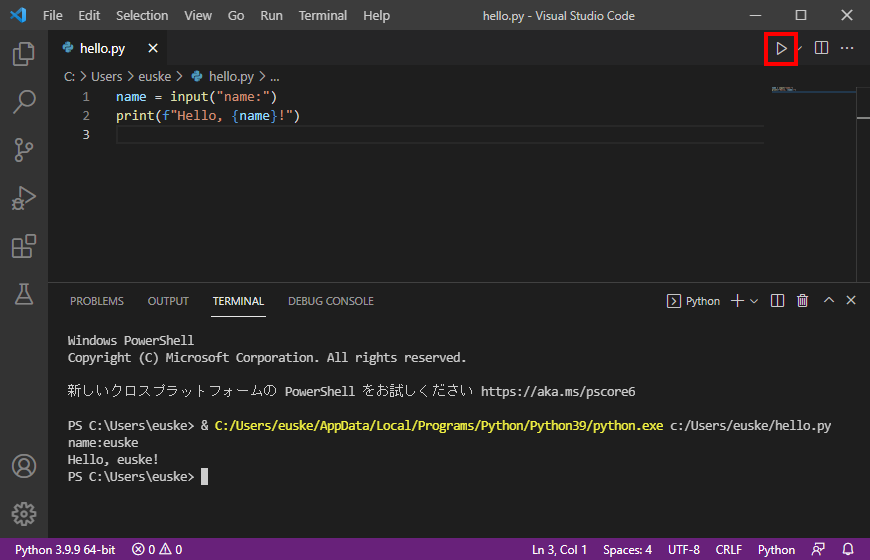
VS Code 上で Python を実行する
VS Code に Python 機能拡張をインストールすると、
編集中の Python プログラムをじかに実行できる。
右上の 再生 ボタンをクリックすればよい。
Jupyter Notebook を使う場合
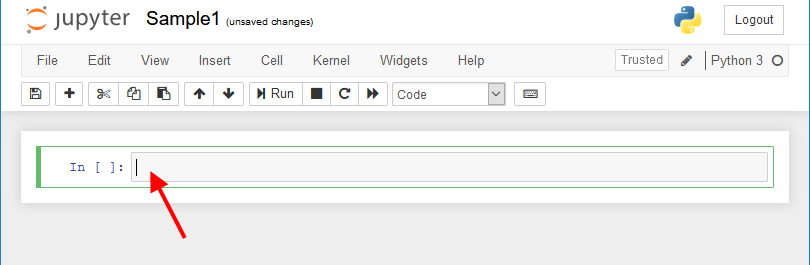
スタートメニューから Jupyter Notebook を起動する。
New Notebook (Python3) を選ぶ。
以下のような画面が出る。この枠内にコードを書き、
Run ボタンを押す。
(あるいは Control + Enter でもよい。)
Google Colaboratory を使う場合
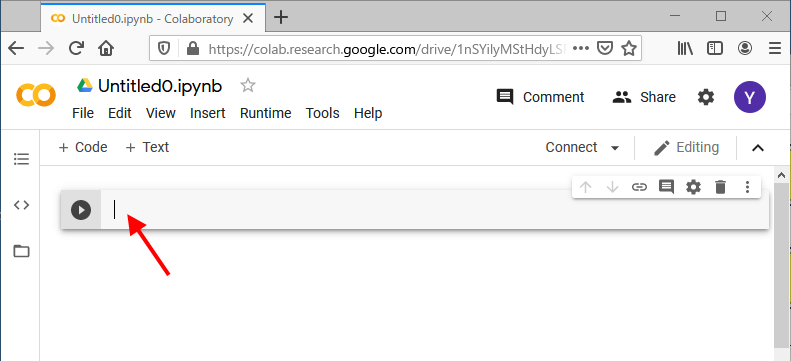
Google Colaboratory にログインする。
File メニューから New Notebook を選ぶ。
以下のような画面が出る。この枠内にコードを書き、
左側の「再生」ボタンを押す。
(あるいは Control + Enter でもよい。)
1.4. ヘルプと文書
Python には簡単なオンラインヘルプがあり、
help() 関数を実行すると、特定の関数やモジュールの仕様を確認できる。
>>> help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
...
ただし help() で表示される内容はやや上級者向けであり、
通常は Web上のドキュメントを参照するほうがよい:
1.5. Python 拡張機能のインストール
Python には非常に多くの拡張機能が用意されている。
これらは Python Package Index というサイトで
一元的に集約されており、pip コマンドで自動的にダウンロード・インストールできる:
C:\Users\euske> pip install numpy
Collecting numpy
Downloading numpy-1.22.1-cp39-cp39-win_amd64.whl (14.7 MB)
|████████████████████████████████| 14.7 MB 364 kB/s
Installing collected packages: numpy
Successfully installed numpy-1.22.1
pip コマンドの代表的な用法は以下のとおり:
書式 説明 例
pip install name 拡張機能 name (およびその依存パッケージ) をダウンロードし、インストールする。
pip install numpy
pip uninstall name インストールされた拡張機能 name を削除する。
pip uninstall torch
pip listインストールされた拡張機能の一覧を表示する。
pip list
pip コマンドでインストールされたファイルは、
Windows の場合は
C:\Users\ユーザ名 \AppData\Local\Programs\Python3.9\Lib\site-packages
以下に、macOS/Linux の場合は (通常)
/usr/lib/python3.9/site-packages 以下に格納される。
Anaconda をインストールしている場合、
condaコマンドで
Anaconda Repository
以下のパッケージもインストールできる。
1.6. 別バージョンのPythonを使う
一部の環境 (Linux や macOS) では、あらかじめ Python がシステムの一部として
組み込まれており、バージョンを選ぶことができない。
このような場合は pyenv というパッケージを使うと、
バージョンが違う Python 実行環境をユーザのホームディレクトリ下に構築できる。
なお、pyenv 自体は
pip ではインストールできず、
ディストリビューション特有のパッケージ管理ツール
(apt-get, pacman, rpm など) を使う必要がある。
pyenv をインストール後、たとえば
Python 3.9.10 をインストールしたい場合は以下のように実行する:
$ pyenv install 3.9.10
Downloading Python-3.9.10.tar.xz...
-> https://www.python.org/ftp/python/3.9.10/Python-3.9.10.tar.xz
Installing Python-3.9.10...
Installed Python-3.9.10 to /home/euske/.pyenv/versions/3.9.10
$ pyenv versions
* system (set by /home/euske/.pyenv/version)
3.9.10
別バージョンの
python (および pip) を実行するには、
まず pyenv global コマンドで使いたいバージョンを設定する:
$ pyenv global 3.9.10
python および pip を実行するかわりに
つねに「pyenv exec python」「pyenv exec pip」のように
記述する:
$ python ...
→ $ pyenv exec python ...pip ...
→ $ pyenv exec pip ...
なお
pyenv上でインストールされた python および
pip が使うディレクトリは、システムとは完全に独立しており、
最初は何も拡張機能がインストールされていない状態になっている。
そのため、必要な拡張機能は pyenv exec pip を使って
適宜インストールする必要がある。
2. Python の基本
Python は言語自体の機能は比較的小さく、
多くの機能はライブラリによって提供されている。
2.1. 文・変数・関数・コメント
以下は基本的な Python のプログラムである。
プログラム中の各行を、それぞれ 文 (statement) とよぶ。
Python はスクリプト言語であり、
各文はインタプリタによって逐次実行される:
hello.py
print("What is your name?")
x = input("name:")
print(f "Hello, {x}!")
# 以降は、コメント とみなされ、無視される。
各文における print(...)、input(...) のような部分を
関数 (function) とよぶ。
print(…) 関数は、文字列を標準出力に表示する。
input(…) 関数は、プロンプトを表示して標準入力から文字列を入力させる。
x のような部分を変数 (variable) とよぶ。
x = input("name:") は代入文 (assignment) である。
代入文の右辺は、式 (expression) である。
Python は文中の式を評価 (eval) して値を決定する。
C などの言語と同じく、式だけからなる文も有効である。
f "〜"f-string と呼ばれ、
文字列中の {…} で囲まれた部分が式として評価され埋め込まれる。
この例では、変数 x の値が展開される。
ソースコードのエンコーディング指定
Python の文字列は、すべて Unicode 文字列である。
デフォルトでは、Python のソースコードは UTF-8 テキストとみなされる。
改行コードは DOS / Unix どちらでもよい。
それ以外の文字コードを明示的に指定したい場合、
ソースコード先頭に coding: で始まるコメントを入れる。
たとえばソースコードが Shift_JIS で書かれている場合は、
ファイル先頭に以下のように書く:
print("こんにちわ。")
2.2. 基本データ型
Python はいわゆる動的型付け 言語であり、
各変数にはあらゆる型の値を格納することができる。
int型
整数型。0x表記をつけると16進数として解釈される。
1729
-3
0x270f
Python の int型には値の上限・下限が存在せず、
メモリの許す限りの桁数が扱える。
int型に対しては以下の演算が使える。
除算 (/) を除いて、intどうしの演算は
つねに intになる。
書式 説明 例
a + b a と b を足した値。2 + 3
a - b a から b を引いた値。y - 1
a * b a と b を掛けた値。x * (n+1)
a // b a を b で割った商。h // 2
a % b a を b で割った余り。(n+1) % 10
a / b a を b で割った値 (結果はfloat)。total / n
a ** b a の b 乗 (a b 2 ** n
a & b a と b のビットごとAND。flag & 63
a | b a と b のビットごとOR。p | 4096
a ^ b a と b のビットごとXOR。q ^ 1
a << n a を n ビット左シフト。1 << k
a >> n a を n ビット右シフト。(x|m) >> 3
Python は、代入演算子もサポートしている:
+=, -=, *=, /=,
%=, //=, **=,
&=, |=, ^=,
<<=, >>=
Python では、代入文は式ではない 。
C や JavaScript と違い、a = (b += 1) のようには書けない
(ただし a = b = 0 は特別に可能である)。
++ および -- 演算子は存在しない。
float型
浮動小数点型。
JavaScript における数値型、C や Java でいう double型に相当する。
表示したときに「.」が含まれるかどうかで int型と区別する。
-3.14
1.4551915228366852e-11
5.
使用可能な演算子は int型と同じだが、
floatとintの演算はつねに floatになる
(いわゆる「型の昇華」)。
>>> 3.14 * 2
6.28
>>> 0.5 + 0.5
1.0
>>> 3 / 4
0.75
str型
いわゆる文字列型。
文字列定数は "〜" あるいは '〜' で表す。
Unicode文字は \uXXXX のように表すことも可能。
Python3 では、ひとつの文字は 1つの Unicodeコードポイントに相当する。
改行を入れたい場合は \n を使う。
Python では「文字」と「文字列」を区別しない。
char型は存在せず、文字を表現したい場合は、
長さ 1 の str型を使う。
"foo bar"
'foo "bar" baz'
'これは\'パイプ\'ではない'
"I\u2665NY"
Python における文字列は変更不能 (immutable) で、
基本的にはひとつの値のように扱われる。
また、Python の文字列は f-string と呼ばれる方法で作成することもできる。
f "…{式 }…"f '…{式 }…'式 の部分が評価され文字列として埋め込まれる
(式 はいくつあってもよい)。
x = 2
y = 3
s = f "{x} plus {y} is {x+y}"
文字列に対しては以下の演算が可能である:
書式 説明 例
s [i ]文字列s の i番目の文字を返す。
name[i ]
s [i :j ]文字列s の i〜j番目の部分文字列 (スライス ) を返す。
path[8 :11 ]
s + t 文字列s と文字列t を連結。
"Good " + "Morning"
s * n 文字列s の n 回繰り返し (n は整数)。
"choo" * 5
len(s )文字列s の長さを返す。
len(name )
s .find(t )文字列s に含まれる文字列 t の位置を返す
(含まれない場合は -1)。
path .find('/' )
s .strip()文字列s の先頭および末尾の空白・改行を切り取る。
(JavaScript では s .trim()
line .strip()
s .split([delim ])文字列s を指定した区切り文字で分割したリストを返す。
buf .split(',' )
文字列の部分列はスライス と呼ぶ。
Python では、負のインデックスは末尾から数えた位置 を表すため、
たとえば以下のような文字列があるとして、
s = "HEADACHE"
この場合の sの各部分は、以下のようになる:
H
E
A
D
A
C
H
E
0
1
2
3
4
5
6
7
8
s[0]
s[-1]
s[2:4]
s[3:-2]
s[:2]
s[5:]
s[-2:]
bool型
いわゆる真理値型。値は True と False の2つしかない。
Bool型の具体的な使い方は、条件式と条件式 の節で述べる。
True
False
None型
「値がない」ときに使われる、
いわゆる null と同じような役割をもつ型。
値は None だけである。
None
型の変換
Python では、データ型は (int → floatへの昇華を除いて)
自動的には型変換されない。
たとえば 123 + "abc" という演算は
TypeError を発生する。
データ型の変換は、以下の関数を使って明示的におこなう:
書式 説明 例
int(x )文字列を整数として解釈。floatを整数に変換。
int('123' )int(3.14 )
int(x , n )文字列をn 進数の整数として解釈。
int('6c1', 16 )
float(x )文字列を小数として解釈。intを小数に変換。
float('3.14' )float(123 )
str(x )数値 (intまたはfloat) を文字列として表現。
str(-2.3 )
ord(x )1文字の Unicodeコードポイントを返す。
ord('あ' )
chr(x )Unicodeコードポイントを長さ1の文字列に変換。
chr(65 )
repr(x )任意のPythonオブジェクト(値)を、正式な文字表現に変換する。abc の文字表現は、
クォートを含む 'abc' である。
repr('abc' )
以下のプログラムが何をするか、実行する前に推測し、
実際に実行して確認せよ。
w = int(input("w:"))
h = int(input("h:"))
area = w*h / 2
print(f"w={w}, h={h}, area={area}")
c = input("character:")
c1 = chr(ord(c)+1)
c2 = chr(ord(c)+2)
print(f"{c} {c1} {c2}")
s = input("path:")
i = s.find("/")
dirname = s[:i]
basename = s[i+1:]
2.3. 条件式と制御文
Python の制御文は、基本的には 3つしかない。
if文、while文 および for文である。
(Python 3.10 では match文が導入されたが、本講座では扱わない。)
if文と while文では、条件式を使う。
Python の比較演算子には、次のようなものがある
(比較の結果はつねに True か False のどちらかとなる):
書式 説明 例
a < b a が b より小さい。y < height
a > b a が b より大きい。(s+t) > m
a == b a と b が等しい。key == 32
a != b a と b が等しくない。status != 0
a <= b a が b 以下。t <= threshold
a >= b a が b 以上。(i+1) >= n
リストおよびタプルに対しては、以下の比較演算子が利用可能である:
x in a 要素 x が a 中に含まれている。
z in [1,3,5,7]
x not in a 要素 x が a 中に含まれていない。
z not in [1,3,5,7]
Python では (int と float を除いて)
異なる型どうしの大小比較はできない。
たとえば "abc" < 123 は TypeError を発生する。
また、(JavaScript とは異なり) 型が異なる値は自動的、変換されないため
"123" == 123 は False となる。
Python における等号 == は、
内容の比較 (Java でいう .equals()) である。
例えば、異なるリストどうしを比較した場合、
すべての要素が一致するかどうかチェックされる。
いっぽうで、参照が等しいかどうかをチェックするには
is 演算子を使う。
これは JavaScript における === 演算子に似ている:
a is b 参照 a と b が等しい。
p[0] is q
a is not b 参照 a と b が等しくない。
x is not None
論理演算子には、次のようなものがある:
書式 説明 例
a and b a および b の両方が真。2 <= x and x <= 5
a or b a または b のどちらか1つ以上は真。x == 0 or y == 0
not a a が真でない。not (x != 3)
論理演算子として && や || は使えない。
いわゆる三項演算子 (? :) は、Python では次のように書く:
(a if c else b )
Pythonでインデントする際の注意
多くの言語で {…} のように表現されるブロックは、
Python では一定幅の インデント (indentation、字下げ) により表現される。
正しく字下げがないソースコードは SyntaxError が発生し、
(部分的にすら) 実行されない。
動かない例 (インデントがない):
s = input("password:")
if s == "sesame":
print("Correct.")
else:
print("Wrong.")
インデントの幅は (一貫しているかぎり) 何文字でもよいが、
一般的な慣例では 半角スペース4個
( ) を使う。
半角スペース以外の文字を使うと動かない。
たとえば以下の例は正しく見えるが、実際にはエラーとなる:
動かない例 (全角スペースが入っている):
s = input("password:")
if s == "sesame":
print("Correct.")
else:
print("Wrong.")
if文
いくつかの構文パターンが存在する。
if節の内部では、
必ずインデントが必要である。
if節のみ
password = input("password:")
if password == "sasami" :
print("Correct.")
print("Good.")
if-else節
x = int(input("x:"))
if 0 < x :
print("positive")
else:
print("zero or negative")
if-elif-else節
x = int(input("x:"))
if 0 < x :
print("positive")
elif 0 > x :
print("negative")
else:
print("zero")
二重のif文
ifやelseのなかに、さらにif文が入ることもありうる。
この場合、「内側のif文」は2重にインデントされる。
a = input("a:")
b = input("b:")
if a == "2" :
if b == "3" :
print("both correct")
else:
print("a is correct")
else:
print("a is not correct")
while文
基本:
i = 0
while i < 10 :
print(f"i={i}")
i += 1
print("end")
break文で抜ける:
whileループ中では、
break文および continue文が使える。
i = 0
while True :
print(f"i={i}")
i += 1
if 10 <= i:
break
print("end")
else節を使う:
Pythonでは、while文の後に else:節を利用できる。
これは whileループが途中で break されず、
ループが最後まで (条件式が真でなくなるまで) 実行されたときにのみ
実行される。
a = [5,9,4,0]
target = int(input("target:"))
while i < len(a) :
if a[i] == target:
print("found")
break
else:
print("not found")
for文
Python の for文は C言語などとは異なり
「リストの各要素を1つずつたどる」動作をする。
これはシェルスクリプトにおける for や、
C# における foreach 文に近い。
基本:
a = [5,9,4,0]
for x in a :
print(f"x={x}")
range()関数を使う:
伝統的な (カウンタを使った) forループを書くには、
range()関数
for i in range (10 ):
print(i)
break文で抜ける:
a = [5,9,4,0]
for x in a :
print(f"x={x}")
if x % 2 == 0:
break
else節を使う:
while文と同様、for文における
else:節も、途中で break されず、
最後まで (すべての要素をたどるまで) ループが実行されたときに
実行される。
a = [5,9,4,0]
target = int(input("target:"))
for x in a :
if x == target:
print("found")
break
else:
print("not found")
pass文
何もしない文。while文などで
中に最低ひとつの文が必要なときに、プレースホルダとして使われる。
C や Java における「;」に近い。
while is_busy():
pass
try…except文
発生した例外を補足する。詳細は エラーと例外 を参照。
Python には switch…case文や、
do…while文は存在しない。
assert文
デバッグ時の検査をおこなう文。
条件式が成立していれば何もせず、
成立していなければ指定されたメッセージとともに
AssertionError を発生する。
assert 0 < x, "x must be positive!"
Python に -O オプションをつけて起動した場合、
assert文は無視される。
与えられた数 n 以下のフィボナッチ数列を表示するプログラムを書け。
n = int(input("n:"))
a = 1
b = 1
...
1〜100 までの素数をすべて表示するプログラムを書け。
for i in range(100):
...
2.4. リストとタプル
Python には可変長の配列として、リスト (list型) と
タプル (tuple型) が存在する。
この2つは機能的によく似ており、Python におけるリストとタプルの違いは
よく取り沙汰される議論であるが、まずはリストから先に説明する。
リストの作成
Python のリストは、いわゆる参照型である。
リストは式が評価 された時点でメモリ上に作成 (new) される。
Python はガベージコレクション (GC) を使っているため、
メモリの解放は自動的におこなわれる。
リストの各要素には、基本型の値や、別のリストを入れることができる。
a = [5, 9, 4, 0]
b = ["foo", "bar", 3.7]
empty = []
table = [[1,2], [3,4], [5,6,7]]
Python のリストでは、各要素ごとに違う型が入ってもよい。
実際には、変数が保持しているのはリストへの参照 であり、
ある参照を別の変数に代入しただけではリストはコピーされない:
a = [5, 9, 4, 0]
b = a
b[0] = 1
「リストのリスト」では、外側のリストの各要素には内側のリストの参照が入っている。
table = [[1,2], [3,4], [5,6,7]]
要素の参照・変更
リストの各要素にはインデックス […] を使ってアクセスできる。
インデックスは 0 から開始する 。
x = a[i]
a[0] = 3
a[n+1] = a[n]
インデックスはつねに int型 である。
インデックスが負の数だった場合、それはリストの末尾から数えた要素になる。
print(a[-1])
print(a[-2])
インデックスが範囲を超えた場合には、IndexError が発生する。
リストのスライス
Python では、リストの部分列を簡単に取り出すことができる。
リストの部分列をスライス という。
たとえば、以下のようなリストがあるとする:
a = [5,9,4,0,7,3,1,8]
このとき aの部分列は、以下のようにして取り出せる。
なお、リストのスライスはつねに新しいリスト が作成される。
a[i :]i >=0 の場合:i 以降の要素
i < 0 の場合:i 番目以降の要素
a[:i ]i >=0 の場合:i までの要素
i < 0 の場合:i が負の場合は末尾からの位置)
a[i :j ]位置 i から位置 j の間にある要素
(このときの長さは j - i 要素)
以下はスライスの例である:
5
9
4
0
7
3
1
8
0
1
2
3
4
5
6
7
8
a[0]
a[-1]
a[2:4]
a[3:-2]
a[:2]
a[5:]
a[-2:]
リストのコピー
リストを複製するには 2つの方法が存在する。
全要素のスライスを作成する方法と、copy()メソッドを使う方法である。
どちらを使ってもよい。
a = [5,9,4,0]
b = a[:]
c = a.copy()
Python におけるリストのコピーは、いわゆる shallow copy である。
「リストのリスト」をコピーした場合、コピーされるのは外側のリストだけで、
内側のリストは共有されている。
要素の追加・挿入・削除
要素の追加・挿入・削除は、
list型のメソッドを使っておこなう。
(歴史的な理由により、削除だけはメソッドではなく del文である。)
書式 説明 例
a .append(x )リスト a の末尾に要素 x を追加。
r .append(2 )
a .insert(i , x )リスト a の i 番目の要素として x を挿入。
args .insert(1 , "foo" )
del a [i ]リスト a の i 番目の要素を削除。 del users [0 ]
リストに対する演算
リストに対しては、以下の演算が使用可能である:
書式 説明 例
a + b リストa とリストb を連結 (新しいリストが作成される)。
[1,2,3] + [4,5,6]
a * n リストa の n 回繰り返し (新しいリストが作成される)。
[0] * 5
len(a )リスト a の長さを返す。
len(args )
sorted(a )リスト a をソートした新しいリストを返す。
sorted([5,9,4,0] )
リストどうしの
+ 演算では新しいリストが作成されるが、
代入演算子
+= を用いた場合、新しいリストは作成されず、
破壊的に要素が追加される 。
a = [5,9]
b = a
a += [4,0]
リスト内包表記 (list comprehension)
Python にはすでに存在するリストの各要素を加工して、
新しいリストを作成するための構文が用意されている。
これをリスト内包表記 という。
リスト内包表記は以下のような形式をもつ:
[ 式 for 変数名 in リスト ]
a = [1,2,3,4,5]
b = [ x*2+1 for x in a ]
内包表記には、if節も追加できる。
こうすると特定の条件を満たす要素だけを抽出できる。
a = [1,2,3,4,5]
e = [ x for x in a if x % 2 == 0 ]
リストとタプルの違い
タプルはリストと似た機能をもつ型としてよく挙げられる。
最初に見た目の違いとして、リストでは各要素を [1,2,3] のように
表現するのに対して、タプルは (1,2,3) のように表現する。
機能的にもっとも大きな違いは、リストは変更可能 (mutable) なのに対して
タプルは変更不能 (immutable) であるということである。
したがってリストでは許される要素の変更や削除などは、
タプルに対しては使えない:
t = (5,9,4)
print(t[0])
t[1] = 3 # TypeErrorが発生
del t[2] # TypeErrorが発生
ではタプルは一体何のために存在するのかというと、
おもに複数の値をまとめる匿名構造体 としてである。
歴史的に Python には C の構造体に相当するものがなく、
バージョン 1.5 でクラスが導入されるまで、
タプルが構造体の代わりに使われていた。
タプルを使うと、通常ひとつの値しか入らない場所
(変数、リストの各要素、関数の返り値など) に複数の値を
「つめこむ」ことができる。(リストでもこれは可能だが、
タプルは変更不能なため、複数の値をまとめたタプルも
依然として「ひとつの値」として扱われる。)
代入文の左辺にタプルを使うと、まとめられた値を複数の変数に分解できる:
user = ('john' , 30 , 6.5 )
(name , age , height ) = user
タプルは任意の長さのものを作成できるが、一度作成されたタプルの
長さが変わることはないため、
この意味で、タプルは数学における伝統的な「ベクトル」に近い
(数学におけるベクトルは、要素数が変化したりしない)。
また、リストの基本的な役割が配列であり、その各要素は
「均質」として扱われるのに対して、タプルは構造体であるため、
タプル中の各要素はそれぞれ別の型・役割をもっていることが多い 。
現在の Python プログラミングにおけるタプルのおもな用途は、
次のとおりである:
リストの要素として:
users = [('john', 30, 6.5) , ('bob', 24, 5.9) ]
関数の返り値として:
def split(name):
return (name[:8], name[8:])
辞書 のキーとして:
d = {(2,3) :6, (-1,0) :7}
タプルは内部的には参照型であるが、
変更不能であるため、リストのように明示的に複製する必要がない。
タプル (の参照) のコピーはつねに同じ値であることが保証される:
a = (5,9,4,0)
b = a
a[0] = 1 # 変更不能。
2.5. 辞書と集合
辞書型
Python における辞書 (dict型) は、
他言語では「ハッシュテーブル」「map型」「連想配列」などと
呼ばれている。辞書を使うと、任意の変更不能な データに、
別の値を関連づけることができる。
これらの値をそれぞれ辞書のキー (key) および バリュー (value) と呼ぶ。
辞書の表面上の使い方は、リストとよく似ている。
リストのインデックスとして int型のかわりに
任意の値が入ると考えればよい:
d = {'abc':123, 'def':456}
print(d['abc'])
d['xyz'] = 999
Python の辞書は、見た目が JavaScript の「オブジェクト」に似ているが、
別の概念である。JavaScript とは異なり、Python では
d['abc'] と
d.abc は異なる意味をもつ。
Python にもいわゆる
「オブジェクト
(インスタンス型) 」は存在するが、
辞書型とは異なる。
辞書のキーは、必ず変更不能な値でなければならない
(辞書のキーが途中で変化すると混乱するためである)。
つまり、リストは辞書のキーになれない 。
ただし、タプルは変更不能であることが保証されているため、
辞書のキーになることができる。タプルのおもな存在理由はこれである:
d = {}
k1 = [1,2,3] # TypeError
d[k1] = 4
k2 = (1,2,3)
d[k2] = 4
辞書の作成
リストと同様、辞書も参照型である。
辞書は式が評価された時点でメモリ上に作成される。
d = {'abc': 123, 'def': 456}
w = {'c':['cat','car'], 'd':['dog','duck']}
empty = {}
files = { 'usr': {'bin': 42, 'lib': 65} }
辞書の各キー・バリューの型は違っていてもよい。
リストと同様に、辞書も内包表記を使って作成することができる:
d = {'abc': 123, 'def': 456}
dd = { k : v*2 for (k,v) in d.items() }
キー・バリューの参照・変更・削除
リストと同様に、[…] 記法を使ってアクセスできる。
v = d['abc']
d['xyz'] = v
del d['xyz']
指定されたキーが辞書中に存在しない場合、
KeyError が発生する。
「存在するかどうかわからないキー」に対する値を取得したい場合は、
後述する .get() メソッドを使うか、以下のように
try…except文を使って KeyError を
補足しなければならない:
try:
v = d[k]
except KeyError:
v = None
辞書に対する操作
辞書に対しては以下のようなメソッド・関数が使用可能である:
書式 説明 例
d .clear()辞書内のキー・バリューを全削除する。
d .clear()
d .copy()辞書をコピー (shallow copy) する。
e = d .copy()
d .get(k , v=None )指定されたキー k に対するバリューを返す。v が返される。
v = d .get(name )
d .keys()辞書 d のキー一覧 (※) を返す。for文で巡回可能。for文で使う場合、.keys() を省略できる)返されるキーの順序は未定義であり、予測不能であるため注意。
for k in d .keys():
print(k)
または
for k in d :
print(k)
d .values()辞書 d のバリュー一覧 (※) を返す。for文で巡回可能。返されるバリューの順序は未定義であり、予測不能であるため注意。
for v in d .values():
print(v)
d .items()(キー , バリュー ) からなる
2要素タプルの一覧 (※) を返す。for文で巡回可能。返されるタプルの順序は未定義であり、予測不能であるため注意。
for (k,v) in d .items():
print(f"{k} -> {v}")
len(d )辞書 d 中のキー・バリューの個数を返す。
n = len(d )
(※) ここで返される「一覧」とはリストではなく、
イテレータ である。
集合型
Python の集合 (set型) は、
文字どおり重複を許さない値の集合である。
これは「辞書のキーのみを取り出した型」とも言える。
集合の各要素は、辞書と同様に変更不能 な値でなければならない。
集合の作成
リスト・辞書と同様、集合は参照型であり、
式が評価された時点でメモリ上に作成される。
s = {'abc', 'def'}
w = set([1, 2, 3])
empty = set()
t = {[1,2,3], [4,5,6]} # TypeErrorが発生
集合中の各要素の型は違っていてもよい。
内包表記を使った作成方法は以下のようになる:
s = {'abc', 'def'}
ss = { x[0] for x in s }
集合型に対する演算
集合型は in演算子または
not in演算子を使って要素が含まれているか否かを判定できる。
s = { 'abc', 'def' }
print('abc' in s)
print('xyz' not in s)
これ以外の集合型に関する演算としては、以下のものがある:
書式 説明 例
s .clear()集合の要素をすべて削除する。
s .clear()
s .copy()集合をコピー (shallow copy) する。
tmp = s .copy()
s .add(x )集合に要素をひとつ追加する。
files .add(path )
s .remove(x )集合から要素をひとつ削除する。KeyError が発生する)
users .remove(uid )
s .union(t )集合 s と t の和集合を返す。
uid = uid .union(added )
s .intersection(t )集合 s と t の積集合を返す。
r = kwd1 .intersection(kwd2 )
s .difference(t )集合 s から集合 t を引いたものを返す。
objs = objs .difference(removed )
s .issubset(t )集合 s が集合 t の部分集合 (subset) であれば真。
if {1,4} .issubset(flags ):
process()
s .issuperset(t )集合 s が集合 t の上位集合 (superset) であれば真。
if not perms .issuperset(a ):
print("denied")
len(s )集合 s の要素数を返す。
print(len(s ))
文字列からなるリスト x を与えると、
もっとも頻出する文字列を選ぶ処理を書け:
x = ['a','b','a','c','b','a']
...
(ちなみに、
同様の処理は collections.Counter クラスを
使えば可能である)
2.6. 関数
Python の関数は、以下のようにして定義する。
関数の内部は、インデントする。
def 名前 (引数1 , 引数2 , ...):
処理
...
return [返り値]
return文の返り値、または
return文全体は省略可能である
(その場合は None が返り値となる)。
あるいは、関数中に複数の returnがあってもよい。
標準的な関数
関数の呼び出し時には、普通の順序で引数を渡す方法と、
キーワード指定 する方法がある。
def avg (x , y ):
a = (x+y)/2
return a
print(avg(3, 5) )
print(avg(x=3, y=5) )
Python の関数は、def文が実行されたときに 定義される。
まだ defが実行されていない時点で利用しようとすると
NameError が発生する。
print(avg2 (3, 5)) # NameErrorが発生
def avg2(x, y):
a = (x+y)/2
return a
デフォルト引数
関数の定義時に、各引数のデフォルト値を定義することができる。
def avg(x=3 , y=5 ):
a = (x+y)/2
return a
print(avg() )
print(avg(1) )
print(avg(x=1) )
print(avg(y=3) )
print(avg(1, 3) )
可変長の引数
可変長の引数を受けとるには、引数名の前に * をつけると
任意の個数の引数からなるタプルとして受け取れる。
引数なしで呼び出した場合、空のタプルが渡される。
def avg(* args):
a = 0
for x in args:
a += x
return a/len(args)
print(avg() )
print(avg(1,3) )
print(avg(1,3,5) )
関数オブジェクト
Python では、関数自体がひとつの値 (オブジェクト) であり、
関数名は実はそのオブジェクトを保持している変数名である。
たとえば print()関数は、実際には
「画面に文字列を表示する関数 (の参照)」がたまたま print という
変数に保持されているにすぎない。その証拠に、以下のようにすると
print() および p() は
まったく同じ関数として扱える:
p = print
p ("hello")
def文は、
関数オブジェクトを変数に代入する文 とみなすことができる:
def foo(x):
...
def p1 (x):
return x+1
def p2 (x):
return x+2
def p3 (x):
return x+3
funcs = [p1 , p2 , p3 ]
for f in funcs:
print(f (123))
以上のように、Python では関数名と変数名は同一の名前空間を使っている。
そのため、同一の名前 (変数) に関数とそれ以外のデータを入れることはできない:
def a(x):
...
a = 1
a () # TypeErrorが発生
クロージャ (closure)
Python では、いわゆるクロージャ が使える。
クロージャとは、関数内で新たに関数を定義したとき、
その関数の外側にある変数が記録され、
アクセスできるようになっているものである:
def makeplus(n):
def plus(x):
return x+n
return plus
f = makeplus(2)
print(f (3))
lambda式
ある種の関数は、(def文を使わずとも) 値として直接表現することが可能である。
これが lambda式である:
def avg(x, y):
return (x+y)/2
avg = (lambda x , y : (x+y)/2 )
lambda 中で表せるのは 1つの値を返す式のみ である。
Python の一般的な構文 (代入文や制御文など) は使うことができない。
Python には、JavaScript における function() { ... } のような、
関数全体をひとつの値として直接表現する方法は存在しない。
その場合は一度 def文を使って変数に代入する必要がある。
global文
Python では、関数の外で (スクリプト中にじかに) 定義されている変数は
すべてグローバル変数 として扱われる。
いっぽう関数内で定義 (代入) されている変数は
ローカル変数とみなされ、外側の変数とは区別される:
foo.py
flag = False
def set_flag():
flag = True
return
上のケースでは、関数 set_flag() 内で
変更している変数 flag は
グローバル変数 flag とは別物なため、
set_flag() を呼んでも
グローバル変数 flag の値は変わらない。
このような事態に対処するため Python では
global文が用意されている。
関数の先頭で、以下のように global文を使うことにより
指定されたグローバル変数にアクセスできるようになる:
flag = False
def set_flag():
global flag
flag = True
return
0 で埋められた二次元リスト (の参照) に対して、
指定された位置 (x,y) および大きさ (w,h) の矩形を
1 で描く関数 drawrect() を定義せよ:
def drawrect(a, x, y, w, h):
...
return
canvas = [ [0]*10 for i in range(10) ]
drawrect(canvas, 0, 0, 10, 10)
drawrect(canvas, 2, 3, 6, 4)
for line in canvas:
print(line)
2.7. エラーと例外
Python では、エラー発生時に必ずトレースバック
(Traceback、いわゆるスタックフレーム) が表示される。
たとえば、以下のプログラムを実行すると:
foo.py
def avg(x, y):
a = (x+y)/2
return a
def main():
print(avg("a", "b"))
main()
以下のトレースバックが表示され、Python は終了する。
トレースバックには各関数の呼び出し位置が、
外側 → 内側の関数の順で 表示される:
Traceback (most recent call last):
File "/home/euske/.../foo.py" , line 8 , in <module> (最外部の発生位置)
main()
File "/home/euske/.../foo.py" , line 6 , in main (main中の発生位置)
print(avg("a", "b"))
File "/home/euske/.../foo.py" , line 2 , in avg (avg中の発生位置)
a = (x+y)/2
TypeError: unsupported operand type(s) for /: 'str' and 'int' (例外の種類および内容)
各呼び出し位置に対して ファイル名 , line 行数 , in 関数名 <module> と表示される)。
最後に、例外の内容が表示される。デバッグするには、
これらの情報をもとにコードを修正すればよい。
Python は (JavaScript などと比べると) 比較的頻繁に
例外 (エラー) を発生させる言語である。
Python における例外は、SyntaxError を除けば、
すべて実行時の例外である。
例外一覧については
Built-in Exceptions
を参照。
よく見かけるエラーの種類を以下に挙げる:
例外 原因 例
KeyboardInterruptionControl + C を押したときに発生する例外。
SyntaxErrorIndentationError
構文エラー。
print("hello"]
NameErrorグローバル変数 ・関数が定義されていない。
a = nonexistent_var
undefined_func (1)
UnboundLocalErrorNameErrorとほぼ同じだが、
関数内で定義された変数 に値がまだ代入されていない場合に起こる。
def foo():
print(x )
x = 1
AttributeErrorオブジェクトの 属性 が定義されていない。
s = "abc"
print(s.foo )
TypeError型の不一致、または関数の引数の不一致。
"abc" / 2
input("abc", "xyz" )
ValueErrorさまざまな関数で、想定外の引数を与えた場合に発生する。
int("よう" )
ZeroDivisionErrorゼロ除算エラー。
2 / 0
IndexErrorリストのインデックスが範囲を超えている。
a = [5,9,4,0]
print(a[4 ])
KeyError辞書 のキーが存在しない。
d = {'abc':123, 'def':456}
print(d['pqrs' ])
UnicodeDecodeError文字列をファイル等から読み込む際に正しくデコードできなかった。
b'\x80 '.decode('utf-8')
UnicodeEncodeError文字列をファイル等に書き込む際に正しくエンコードできなかった。
'あ '.encode('ascii')
OSErrorOSレベルで発生する入出力関連のエラー。
open('nonexistent_file' )
AssertionErrorassert文の条件が成立しなかったときに発生する。
assert 2+2 == 5
Python では、エラーと例外の間に明白な区別がない。
try…except文による例外の補足
Python の例外は、Java や C++ の例外と同様に
例外オブジェクトを使っている。すべての例外は
try…except文によって補足できる。
try…except文は、
ひとつのtry節と複数のexcept節からなる:
try:
なんらかの処理
except 例外クラス1 as 変数名1 :
例外処理1
except 例外クラス2 as 変数名2 :
例外処理2
...
例外クラスには上に挙げた例外のどれかを指定する:
try:
n = int(input("number:"))
print(f"n={n}")
except ValueError as e :
print("not a number")
上の例で、補足された例外オブジェクトは変数 e に格納される。
ここには普通は例外の内容が e.args に含まれており、
トレースバック情報も含まれている (が、詳細は省略する)。
実際には (Javaなどと同様に) Python の例外クラスは階層化されており、
except節には当該する例外クラスか、その基底クラスを
指定してもよい。すべての例外の基底クラスは
Exception であるので:
try:
なんらかの処理
except Exception as e :
例外処理
2.8. イテレータ
Python のプログラムでは イテレータ (iterator) がよく使われる。
簡単にいえば、イテレータとは
「for文で巡回可能な値の列d .keys()
イテレータの基本
以下はイテレータの基本的な使用例である。
まず iter() 関数でリストの各要素をたどるイテレータを作成し、
next() 関数でそれを1つずつ巡回する。
それ以上の要素がなくなると StopIteration例外が発生する。
a = [1,2,3]
it = iter(a)
print(next(it) )
print(next(it) )
print(next(it) )
print(next(it) )
実際には、上のような方法でイテレータを使うことはまずない。
イテレータに対して for文を使えば、
以上の処理が簡単に書けるためである:
a = [1,2,3]
it = iter(a)
for x in it:
print(x)
さらに、for文は与えられたオブジェクトのイテレータを自動的に生成するため、
実は iter() 関数すら必要ない。
一般的に、イテレータ型を受けつける部分には
リスト・タプル・文字列・集合などの型も受けつける 。
a = [1,2,3]
for x in a :
print(x)
range()関数
おそらくもっともよく使われるイテレータが range() 関数である。
これはおもに for文で伝統的な
(カウンタを使った) ループを表すのに使われる:
for i in range(10 ):
print(i)
for i in range(10 , 20 ):
print(i)
for i in range(0 , 10 , 2 ):
print(i)
イテレータの合成
Python では、イテレータを合成する関数がいくつか用意されている。
これはあるイテレータを受けとり、その各要素になんらかの処理をほどこし、
ふたたびイテレータとして出力するものである。
書式 説明 例
enumerate(it )イテレータ it の各要素にインデックスを付加する。a ,b ,c ,…(0,a ),(1,b ),(2,c ),… という
2要素タプルの列に変換される。
a = ['abc','def','xyz']
for (i,x) in enumerate(a ):
print(i,x)
map(f , it )イテレータ it の各要素に関数 f を適用する。a ,b ,c ,…f (a ),f (b ),f (c ),…
a = [1,2,3]
for x in map(str , a ):
print(x)
zip(it1 , it2 , …)イテレータ it1 , it2 , ...の各要素を
ひとつのタプルにまとめる。a ,b ,c ,…x ,y ,z ,…(a ,x ),(b ,y ),(c ,z ),… に変換される。
a = ['abc','def','xyz']
b = [1,2,3]
for (x,y) in zip(a , b ):
print(x, y)
イテレータを受けとる関数
書式 説明 例
list(it )イテレータ it をリストに変換する。
a = list(it )
tuple(it )イテレータ it をタプルに変換する。
t = tuple(it )
sum(it )イテレータ it の数値をすべて合計する。
sum(range(1,5) )
min(it )イテレータ it の最小値を返す。
min([5,9,4] )
max(it )イテレータ it の最大値を返す。
max(scores )
s .join(it )イテレータ it の文字列を区切り文字 s で連結する。
'\n' .join(lines )
イテレータに len() 関数を使うことはできない。
ジェネレータ式 (generator expression)
リスト内包表記 に似た書式で
[…] のかわりに (…) を使うと、
リストのかわりにイテレータが返される。これをジェネレータ式 とよぶ:
a = [1,2,3,4,5]
b = ( x*2+1 for x in a )
for x in b:
print(x)
ジェネレータ関数 (generator function)
イテレータは通常、なんらかの内部状態を保持する必要があるが、
Python の yield文を使うと、
イテレータを通常のプログラムのように簡単に記述できる。
このような関数をジェネレータ と呼ぶ。
関数定義の中で yield文が使われていると、
その関数はジェネレータとみなされる。通常の関数とは異なり、
ジェネレータは段階的に実行される 。
def g():
i = 1
while True:
yield i
i += 2
for n in g():
print(n)
上の例にあるように、ジェネレータ関数は終了しなくてもかまわない。
具体的には、ジェネレータ関数は以下のように実行される:
まず、関数が返すイテレータの最初の値が要求されるまで、
関数本体は実行を開始しない。
イテレータの要素がひとつ要求されたら、関数は yield
文に到達するまで実行される。
値がひとつ生成され、イテレータの消費側に渡されると、
次の要素が要求されるまで関数の実行は止まる。
ジェネレータ関数は必ずイテレータを返すため、
return文による返り値は無視される。
2.9. クラスとインスタンス
Python では、オブジェクト指向はどちらかといえば付け足し的な扱いであり、
(Javaのように) なんでもクラス化することが推奨されているわけではない。
クラスを使わない Python プログラムも多く存在する。
Python におけるクラスの用途は、おもに次の2つである:
なんらかの内部状態をもつオブジェクトを実装したいとき。
単にデータをまとめる構造体として。
Python でクラスを扱う場合は、インスタンス 型を使う。
これは一連の手続き (メソッド) にデータが付随したものである。
すべてのインスタンスは、そのテンプレートである
クラス から実体化される。
Python における「オブジェクト」という用語には注意が必要である。
Java や C++ などの言語における「オブジェクト」は、
クラスから作成したインスタンスのことだが、
Pythonではどんな値も「オブジェクト」である 。
混乱を避けるため、ここではクラスから作成した実体はつねに
「インスタンス」 と呼ぶことにする。
以下は Python の典型的なクラス定義と使用の例である
(Python では、クラス名は大文字から始めることが多い) :
class Counter :
def __init__ (self, count):
self.count = count
def inc (self, n):
self.count += n
return self.count
c = Counter(0)
print(c.inc(1))
print(c.inc(1))
print(c.inc(1))
クラスの定義
クラスの定義は class文で始める。
Java などと違って、
Python ではインスタンス変数をあらかじめ宣言する必要はなく、
ひとつのインスタンス中にあとからいくらでも変数を追加できる。
次に、インデントされた各メソッドを記述する。
上の例では、メソッド __init__ および inc が
定義されている。__init__メソッドはコンストラクタ であり、
そのインスタンスが作成されるときに最初に呼ばれる
(なお、コンストラクタは省略可能である)。
インスタンスに所属する変数は、
ふつうコンストラクタ (__init__メソッド) で初期化される。
上の例では count というインスタンス変数が初期化されている。
Python では、インスタンスに所属する変数を、オブジェクトの
属性 (attribute) と呼ぶ。属性は、c .count. をつけることで参照・変更できる。
Python では「暗黙の変数スコープ」は存在しない。
メソッド内でインスタンス変数にアクセスする際には必ず
self. をつける必要がある。
同様に、同一クラス内のメソッド呼び出しも単に foo() とはできず、
必ず self.foo() のように書く必要がある。
なお self はただの変数名であり、
this のような特殊なキーワードではない
(self という名前は慣例にすぎない)。
関数と同様、Python のクラスは class文が実行されたときに 定義される。
また、関数オブジェクトと同様に、Python ではクラスもひとつの値である。
つまり class文は、実際には
クラスオブジェクトを変数に代入する文 である:
class Counter:
...
実際、Counter クラスを別の変数に代入すれば、
その名前はクラスと同様に扱うことができる:
T = Counter
c = T (0)
メソッドの定義
Python では、各メソッドの第1引数は必ず self でなければならない。
(実際には他の名前もつけられるが、self が慣例である。)
Python では自分自身のインスタンスを表す this キーワードは
存在せず、インスタンスへの参照はつねにメソッドの第1引数 self に渡される。
ただし、引数として self が現れるのは定義だけであって、
メソッド呼び出し時には self を除いた引数を渡す 。
上に挙げた Counterクラスを再掲すると、以下のようになる:
class Counter:
def __init__(self , count ):
self.count = count
def inc(self , n ):
self.count += n
return self.count
c = Counter(0 )
print(c .inc(1 ))
インスタンスの作成とメソッドの呼び出し
Python には、new演算子は存在しない。
あるクラスのインスタンスを作成するには、
そのクラス名 (クラスオブジェクト) を関数のようにして呼ぶだけでよい。
ここで渡した引数はコンストラクタ (__init__メソッド) の
引数として渡される:
c = Counter(0)
メソッド呼び出しは Java などの言語と似ているが、
Python ではメソッドとは、単にクラスに所属し、
あらかじめ第1引数が束縛されている関数オブジェクト にすぎない。
以下の3つの関数 (メソッド) 呼び出しはどれも同じ効果をもつ:
print(c.inc(1) )
func = c.inc
print(func(1) )
print(Counter.inc(c, 1) )
JavaScript とは異なり、Python のメソッドは
実際に self が束縛されたクロージャである。
クラスの継承
Python では、クラスを継承するには class文で
基底クラスを (…) で囲んで表示する。
ここでは上の Counterクラスを継承し、__init__ と
incメソッドを上書きした DoubleCounterクラスを定義している:
class DoubleCounter(Counter ):
def __init__ (self, count):
super() .__init__(count*2)
def inc (self, n):
self.count += n*2
return self.count
基底クラスの class文は、
必ず派生クラスの定義よりも前に実行されている必要がある。
さもないと NameError が発生する。
基底クラスのメソッドを呼ぶには、
super() 関数を使う。
こうするとクラスが多重継承である場合に、
基底クラスのメソッドを正しい呼び出し順序 (MRO) で実行できる。
クラスとインスタンスに対する演算
クラスやインスタンスの関係を検査するために、以下の関数が用意されている:
書式 説明 例
type(x )インスタンス x が所属するクラスを返す。
if type(c ) == Counter:
c.inc(1)
isinstance(x , t )インスタンス x がクラス t (あるいはその派生クラス) に
所属していれば真。
if isinstance(c , Counter ):
c.inc(1)
issubclass(s , t )クラス s がクラス t の派生クラスであれば真。
assert issubclass(DoubleCounter , Counter )
実は Python では「型 (type)」と「クラス (class)」はほぼ同義 である。
int型や str型などは内部的に
クラスとして扱われており、実際、int や str といった
名前はクラスオブジェクト (typeオブジェクト) が
入っている変数にすぎない。(int() や str() 関数は、
実際にはコンストラクタである。)
したがって、上の3つの関数は実際にはクラスだけでなく、
あらゆる値の型検査に使える:
if isinstance(x , int ):
print(x+1)
特別なメソッド
Python のクラスは、特定の名前をもつメソッドを定義することにより、
インスタンスに特別な機能を持たせることができる。
よく使われるものを以下に示す
(完全な一覧については Pythonリファレンスマニュアルの
3.3. "Special method names" を参照):
書式 説明 例
__repr__(self)インスタンスの「正式な」文字表現を返す。
このインスタンスに対して repr() 関数が
実行されたとき、このメソッドの返り値が使われる。
def __repr__(self):
return f'<count={self.count}>'
__str__(self)インスタンスの「表示用の」文字表現を返す。
このインスタンスに対して str() 関数が
実行されたとき、このメソッドの返り値が使われる。
def __str__(self):
return f'<{self.count}>'
__len__(self)インスタンスの「サイズ」を返す。
このインスタンスに対して len() 関数が
実行されたとき、このメソッドの返り値が使われる。
リストや文字列のようなふるまいをインスタンスに持たせるときに使う。
def __len__(self):
return 1
__getitem__(self, k )インスタンス x に対して、添え字による参照
x [k ]
def __getitem__(self, k):
return k * 2
__setitem__(self, k , v )インスタンス x に対して、添え字による代入
x [k ] = v
def __setitem__(self, k, v):
print(f'set {k} to {v}')
__call__(self, arg1, … )インスタンス x に対して関数呼び出し
x (arg1 , …)
def __call__(self, x ):
return x*2
__iter__(self)インスタンス x に対して (for文などで)
イテレータが要求されたときに、このメソッドの返り値が使われる。
ジェネレータ関数であってもよい。
def __iter__(self):
yield 1
yield 2
yield 3
__eq__(self, x )このインスタンスが == 演算子で
他のオブジェクト (同じクラスとは限らない) と比較されたときに
このメソッドが返り値が使われる。
def __eq__(self, c):
return (isinstance(c, Counter) and
self.count == c.count)
以下のクラス Parser のメソッドを完成させよ。
これはカンマ (,) で区切られた要素列を文字列のリストに
変換するパーザで、"〜"内に囲まれた部分ではカンマは
区切り文字として認識されない (エスケープされる)。
.feed() メソッドは、文字を 1文字ずつ入力し
内部状態を変化させ、
.get() メソッドで最終的な結果を取得するものとする。
class Parser:
def __init__(self):
self.result = []
self.inquote = ''
self.buf = ''
def feed(self, c):
...
return
def get(self):
...
return self.result
s = 'abc,"de"f,"p,qr"'
p = Parser()
for c in s:
p.feed(c)
print(p.get())
2.10. ファイル入出力
Python では基本的な (ストリームによる)
ファイル操作が標準でサポートされている。
ファイルを開く・閉じる
以下は Python による基本的なファイル操作の手順を示したものである:
fp = open ('path/to/file')
line = fp .readline()
# ファイルを閉じる (非推奨)。
fp .close ()
Python では open() 関数によりファイルを開く。
このときファイルオブジェクト が返されるので、それに対して
読み書きの操作をおこなう。ファイルを閉じるには、
close()メソッドを実行する。
ファイルオブジェクトは1種類ではない。
open() はファイルを開くモード (後述) や
バッファの有無によって異なった型のオブジェクトを返すが、
この差をユーザが意識する必要はほとんどない。
ここではひとまとめにファイルオブジェクトと呼ぶことにする。
実は、上に示したやり方は現在は推奨されない 。
なんらかの原因で fp.close() が実行されない場合
OS上のファイル記述子がリークしてしまうので、
現在では以下のような with文を使った方法が推奨されている:
with open ('path/to/file') as fp :
line = fp .readline()
(with文の動作の詳細については Pythonリファレンスマニュアルの
3.3.9. With Statement Context Managers を参照)
open() 関数の引数にはさまざまなオプションがある。
代表的なものを以下に紹介する:
書式 説明 例
open(path )テキストファイル path (UTF-8エンコーディング) を読み込みモードで開く。
fp = open('/etc/motd' )
open(path , encoding=e )テキストファイル path (エンコーディング e ) を
読み込みモードで開く。
fp = open('readme.txt' , encoding='cp932' )
open(path , 'w')テキストファイル path を書き込みモードで開く
(ファイルの内容はクリアされる)。
fp = open('/tmp/foo' , 'w')
open(path , 'a')テキストファイル path を追記モードで開く
(ファイルがない場合は作成される)。
fp = open('out.log' , 'a')
open(path , 'rb')バイナリファイル path を読み込みモードで開く。
fp = open('foo.jpg' , 'rb')
open(path , 'wb')バイナリファイル path を書き込みモードで開く
(ファイルの内容はクリアされる)。
fp = open('dump.dat' , 'wb')
open(path , 'rb+')バイナリファイル path を読み書き込みモードで開く
(ファイルがない場合は作成される)。
fp = open('update.db' , 'wb+')
テキストファイルを読み書きする
ファイルをテキストファイルとして読み込む場合、
Python は自動的にそのファイルの文字コード変換
(デフォルトは UTF-8) および改行コードの変換をおこなう。
通常のテキストファイルでは "universal newline" モードが有効になっており、
ファイル中の改行コードが
CR (\r), LF (\n), CR+LF (\r\n)
のどれであっても 1行として認識され、改行文字は
自動的に str型の '\n' に変換される。
テキストファイルからデータを読み込む・書き込むには、
以下の方法が用意されている:
書式 説明 例
fp .read([n] )ファイル fp から n 文字を読み込む。
n が省略された場合はファイルの終わりまで読み込む。
print(fp .read())
fp .readline()ファイル fp から1行分 (改行まで) の文字列を読み込む。
line = fp .readline()
iter(fp )ファイル fp の各行を文字列のイテレータ として返す。
for line in fp :
print(line)
fp .write(s )ファイル fp に文字列 s を書き込む。
fp .write('howdy!\n' )
バイナリファイルを読み書きする
バイナリファイルを読み書きする場合、Python ではbytes型を使う。
bytes型は見た目・機能ともstr型に似ているが、
各要素は Unicode文字ではなく、0〜255の範囲をもつ整数である。
Bytes型の定数は b '〜'
b'abc'
b'\x0d\x0a'
文字列とは異なり、bytes型の各要素は「長さ1のbytes型」ではなく
int型である 。
ただし、bytes型のスライス はbytes型である:
また、文字列と同じくbytes列は読み込み専用である。
つまり各要素を取り出すことはできるが、変更することはできない。
b = b'ABC'
print(b[1])
print(b[1:2])
b[1] = 100 # TypeError が発生
str型をバイナリファイルとして読み込み・書き込みをする場合、
明示的にbytes型と型変換しなければならないので注意が必要である。
bytes型→str型への変換 (デコード ) には decode() メソッドを、
str型→bytes型への変換 (エンコード ) には encode() メソッドを使う:
b = fp.read(3)
s = b .decode ('utf-8' )
print(s)
s = 'あ'
b = s .encode ('cp932' )
fp.write(b)
バイナリファイルからデータを読み込む・書き込むには、
以下の方法が用意されている:
書式 説明 例
fp .read([n] )ファイル fp から n バイトを読み込む。
n が省略された場合はファイルの終わりまで読み込む。
b = fp .read(4 )
fp .seek(offset [, whence=0] )ファイル fp の特定の位置 offset から読み込みを開始する。
whence が 0 の場合、offset は絶対位置をあらわし、
1 の場合は相対位置、2 の場合はファイル末尾からの相対位置をあわわす。
fp .seek(4096 )
fp .tell()ファイル fp の現在位置を返す。
pos = fp .tell()
fp .write(b )ファイル fp にバイト列 b を書き込む。
fp .write('よう'.encode('utf-8') )
3. Python の拡張機能
Python におけるモジュール とは、簡単にいえば
別のプログラムから利用できる Python スクリプト
(ファイル) のことである。
ただし Python においてはモジュールは単なるファイルではなく、
実際に値を参照したり代入したりできるオブジェクトとして扱われる。
なお、Python では「モジュール」と「ライブラリ」はほぼ同じ意味である。
本節ではまずユーザがモジュールを定義・利用する方法を説明する。
つぎに Python でデータ処理をする際に
よく使われるモジュールの使用例を紹介する。
Python モジュールの検索パスは、通常は
「実行するスクリプトが置かれているディレクトリ +
環境変数 PYTHONPATH + システム標準」が使われる。
システム標準は Python のディストリビューションによって異なっているが、
pip あるいは conda などでモジュールを
インストールした際には必ずシステム標準のパスで発見できるように
なっている。
3.1. モジュールの定義と使用
以下は Python によるモジュールの例である:
foo.py
num = 1729
def avg (x, y):
a = (x+y)/2
return a
class Counter :
def __init__(self, count):
self.count = count
def inc(self, n):
self.count += n
return self.count
このモジュールでは、変数num、
関数avg、およびクラスCounter が定義されている。
Python では、関数定義・クラス定義は
どちらも変数へのオブジェクトの代入であるので、
実際には上の foo モジュールは
3つの属性 (foo.num、foo.avg および
foo.Counter) をもつオブジェクトとみなせる。
Python では、モジュールとインスタンスは見た目上は区別できない。
たとえば foo.num は foo というインスタンスの属性かもしれないし、
foo というモジュールで定義された変数かもしれない。
Python においては、どちらも特定の名前空間の属性 なのである。
モジュールを利用するには、import文を使う。
Pythonインタプリタは、実行するスクリプトと同じディレクトリ
(あるいは環境変数 PYTHONPATH で指定されているディレクトリ)
上にある foo.py を読み込み、def文や class文などを
実際に実行して関数・クラスを定義する:
import foo
print(foo.num )
print(foo.avg (3, 5))
c = foo.Counter (1)
実際には、import文もまた
変数への「モジュールオブジェクト」の代入とみなせる。
import文には以下の4種類の表記があり、
モジュール内のオブジェクトをどのように参照するかによって使いわける:
import foo
import foo as bar
from foo import num
from foo import num as spam
モジュール内のすべてのオブジェクトを現在の名前空間に取り込むには、
以下のように *表記を使う (この方法は推奨されていない):
from foo import *
階層的なモジュール
さらに、モジュールはディレクトリ (フォルダ) によって階層化できる。
複数のモジュールをまとめたモジュールをパッケージ (package) と呼ぶ。
たとえば、あるディレクトリ mypkg をパッケージとして利用するには、
以下のようにファイルを配置する:
mypkg/ (ディレクトリ)
__init__.py (ファイル)
foo.py (ファイル)
bar.py (ファイル)
mypkg
foo
- num
- avg
- Counter
bar
...
ディレクトリを Python パッケージ (モジュール) として認識させるためには、
必ず __init__.py ファイルが必要である
(内容は空でもよい)。__init__.py ファイル内で
変数・関数・クラスを定義した場合、それらは
mypkg モジュールの属性として利用できる。
パッケージもモジュールであるので、普通に import文で利用できる:
import mypkg.foo
print(mypkg.foo.num)
from mypkg import foo
print(foo.num)
モジュール単体での利用
通常、Python のモジュールに含まれる文は基本的に代入文
(変数への代入や、def文および class文) だけである。
なぜならモジュールの中身は import時にスクリプトとして
実際に評価 (実行) されるため、たとえば print() などを書いておくと
import時に余計な副作用が発生してしまうためである。
ただし、(テストなどの目的で) ときにモジュール用の
Python スクリプトを単体でも実行したいときがある。
このような場合は、以下のようなトリックを使う:
foo.py
num = ...
def avg(x, y): ...
class Counter: ...
if __name__ == '__main__':
print('Hello')
変数 __name__ は現在 importしている
モジュール名をあらわす特殊変数で、スクリプトが単体で実行された場合、
この値はつねに '__main__' となるため
if文の中が実行される:
C:\Users\euske> python foo.py
Hello
C:\Users\euske> python
>>> import foo
>>>
3.2. Python の標準ライブラリ
Python では「Battery included (電池つき)」の考え方により、
多くのモジュールが標準搭載されている。その分野は
ファイル処理からネットワーク処理、HTMLや電子メールの解析から
端末制御や共有ライブラリ中の C APIの呼び出しまでさまざまである:
これらの標準ライブラリのコードは、Windows の場合
C:\Users\ユーザ名 \AppData\Local\Programs\Python3.9\Lib
以下に、macOS/Linux の場合は (通常)
/usr/lib/python3.9 以下に格納されている。
以下によく使われるモジュールを挙げる:
3.3. コマンドライン引数を解析するには
Python でコマンドラインからの引数を解析するには、
sysモジュールsys.argv にはプロセス起動時の
各引数 (C でいう char** argv) が
str型のリストとして格納されており、
sys.argv[0] はコマンド名に相当する:
import sys
if __name__ == '__main__':
args = sys.argv [1:]
さらに、
argparse.ArgumentParser クラス
if __name__ == '__main__':
from argparse import ArgumentParser
parser = ArgumentParser ()
parser.add_argument('-f' , '--file' , dest='filename' ,
help='file name to process' , metavar='FILE' )
parser.add_argument('-v' , '--verbose' ,
action='store_true' , dest='verbose' , default=False ,
help='print debug messages' )
args = parser.parse_args()
print(args.filename)
print(args.verbose)
3.4. CSVファイルを読み書きするには
Python で CSVファイルを読み書きするには、
csv モジュールcsv.reader() を使い、
CSV の各行を返すイテレータを取得する:
import csv
with open('input.csv', encoding='cp932') as fp:
for row in csv.reader(fp ):
print(row)
書き込みには csv.writer() を使う。
ここで返される writerオブジェクトに対して
writerow() メソッドを呼び、
1行ずつ出力する:
import csv
with open('output.csv', 'w') as fp:
writer = csv.writer(fp )
for row in rows:
writer.writerow(row )
3.5. JSONファイルを読み書きするには
Python で JSONファイルを読み書きするには、
json モジュール
import json
text = '{"foo": "bar", "baz": [1, 2, 3]}'
obj = json.loads(text )
print(obj)
with open('input.json') as fp:
obj = json.load(fp )
以下は JSON 形式を出力する例である:
import json
obj = {'foo': 'bar', 'baz': [1, 2, 3]}
print(json.dumps(obj ))
with open('output.json') as fp:
json.dump(obj , fp )
3.6. ZIPファイルを読み込むには
Zipファイルの読み書きには、
zipfileZipFileZipInfo.open() メソッドに渡し、
各ファイルの内容を取得する。
なお zip に格納されたファイルはすべてバイナリファイルとして扱われる。
import zipfile
with zipfile.ZipFile('input.zip' ) as zfp:
for info in zfp.infolist():
print(info.filename)
with zfp.open(info) as fp:
data = fp.read()
3.7. XMLファイルを読み込むには
Python で XML を処理するにはいくつかの方法があるが、
もっとも手軽なのは xml.etree.ElementTree モジュール
input.xml
<?xml version="1.0"?>
<group>
<person id="1">john</person>
<person id="2">mary</person>
</group>
このような XML を処理するプログラムは以下のようになる:
from xml.etree.ElementTree import XML
with open('input.xml') as fp:
root = XML(fp.read())
assert root.tag == 'group'
for elem in root:
if elem.tag == 'person':
print(elem.get('id'))
print(elem.text)
3.8. 画像ファイルの処理
Python で画像ファイルを扱うモジュールは多数存在するが、
ここでは広く使われている
Pillow という
モジュールを使う。
Pillow はデフォルトでは含まれていないため、
pip を使ってインストールする:
C:\Users\euske> pip install pillow
Collecting pillow
Downloading Pillow-9.0.0-cp39-cp39-win_amd64.whl (3.2 MB)
|████████████████████████████████| 3.2 MB 2.2 MB/s
Installing collected packages: pillow
Successfully installed pillow-9.0.0
Pillow は標準で PNG, JPEG, TIFF などの画像ファイル形式をサポートしている。
以下のようにすると、現在サポートするファイル形式一覧が表示される:
C:\Users\euske> python -m pip
Pillow を使った典型的な画像の読み込み、情報の取得、切り取り、
リサイズ、保存をする一連のプロセスは以下のようになる。
(なお、Pillow はもともと PIL (Python Imaging Library) の
互換モジュールとして開発されたため、モジュール名は PIL となっている。)
from PIL import Image
img = Image.open('input.jpg')
print(img.width, img.height, img.mode)
img = img.crop((100, 200, 100, 100))
img = img.resize((50, 50))
img.save('output.jpg')
Pillow の画像オブジェクトは PIL.Image.Imageインスタンスとして
表現されるが、ユーザがこのインスタンスを直接作成することはなく、
通常は Image.open などの関数を使って作成する。
また、切り取りやリサイズ等の操作ではもとの画像は変化せず、
つねに新しい画像が返される。
さらに Pillow の画像オブジェクトは、後で紹介する NumPy の
ndarray型
from PIL import Image
import numpy as np
a = np.array.zeros((10, 10, 3))
img = Image.fromarray(a)
img = Image.open('input.jpg')
a = np.array(img)
画像オブジェクトに対するおもな操作を以下に示す:
書式 説明 例
Image.open(path )画像ファイル path を読み込み、画像オブジェクトを返す。
img = Image.open('input.jpg' )
img .save(path)画像 img をファイル path に保存する。
ファイル形式は拡張子に応じて決められる。
out .save('output.png' )
img .copy()複製した画像を返す。
img2 = img .copy()
img .resize((w , h ))画像 img を w ×h ピクセルにリサイズした画像を返す。
img = img .resize((img.width//2, img.height//2) )
img .crop((x0 , y0 , x1 , y1 ))画像 img の一部を (x0 , y0 , x1 , y1 ) の矩形で切り取った画像を返す。
img = img .crop((0, 0, 100, 100) )
dst .paste(src, (x0 , y0 , x1 , y1 ))画像 src を画像 dst 内の位置 (x0 ,y0 ,x1 ,y1 ) に描画する。
out .paste(img , (x,y,x+img.width,y+img.height) )
img .thumbnail((w , h ))画像 img を w ×h ピクセルに入るように変更する。このとき、画像の縦横比は保存される。
img .thumbnail((100, 100) )
img .width画像の幅を返す。
img .height画像の高さを返す。
img .mode画像のピクセル形式を文字列
('RGB', 'RGBA' など) で返す。
(一覧 )
Yusuke Shinyama